



Poolside AI has unveiled the first two models in its Laguna series: Laguna M.1 and Laguna XS.2. Alongside these releases, the company is also introducing pool — a lightweight, terminal-based coding agent and a dual Agent Communication Protocol (ACP) client-server environment. This is the same internal setup Poolside uses for agent reinforcement learning (RL) training and research, now available as a research preview.
Understanding These Models and Their Significance
Both Laguna M.1 and Laguna XS.2 are built on a Mixture-of-Experts (MoE) architecture. Unlike traditional models that activate every parameter for each token, MoE models selectively route each token through only a subset of specialized sub-networks known as “experts.” This approach allows for a large total parameter count — and the expanded capacity that comes with it — while only incurring the computational cost of a much smaller number of “active” parameters during inference.
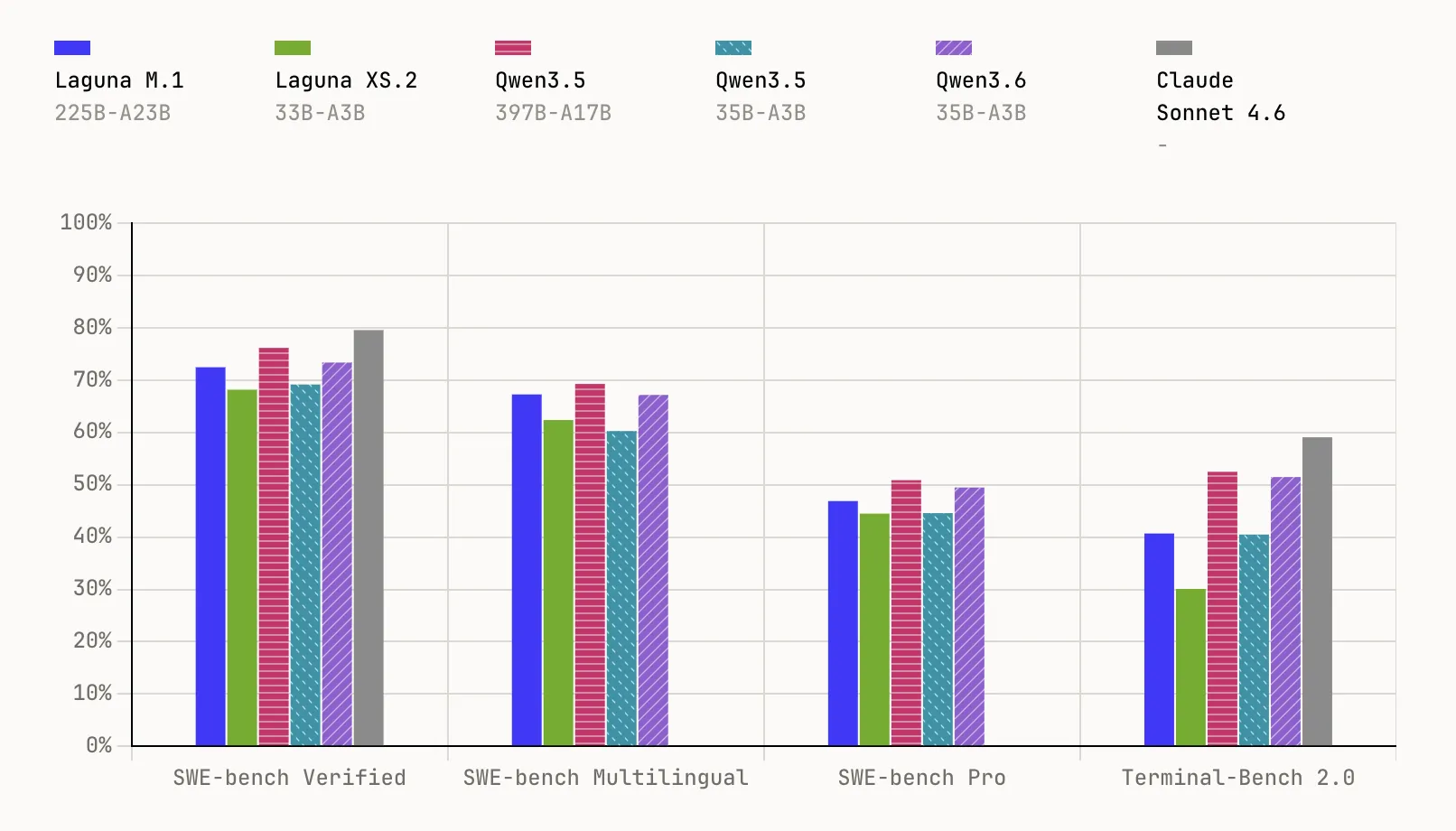
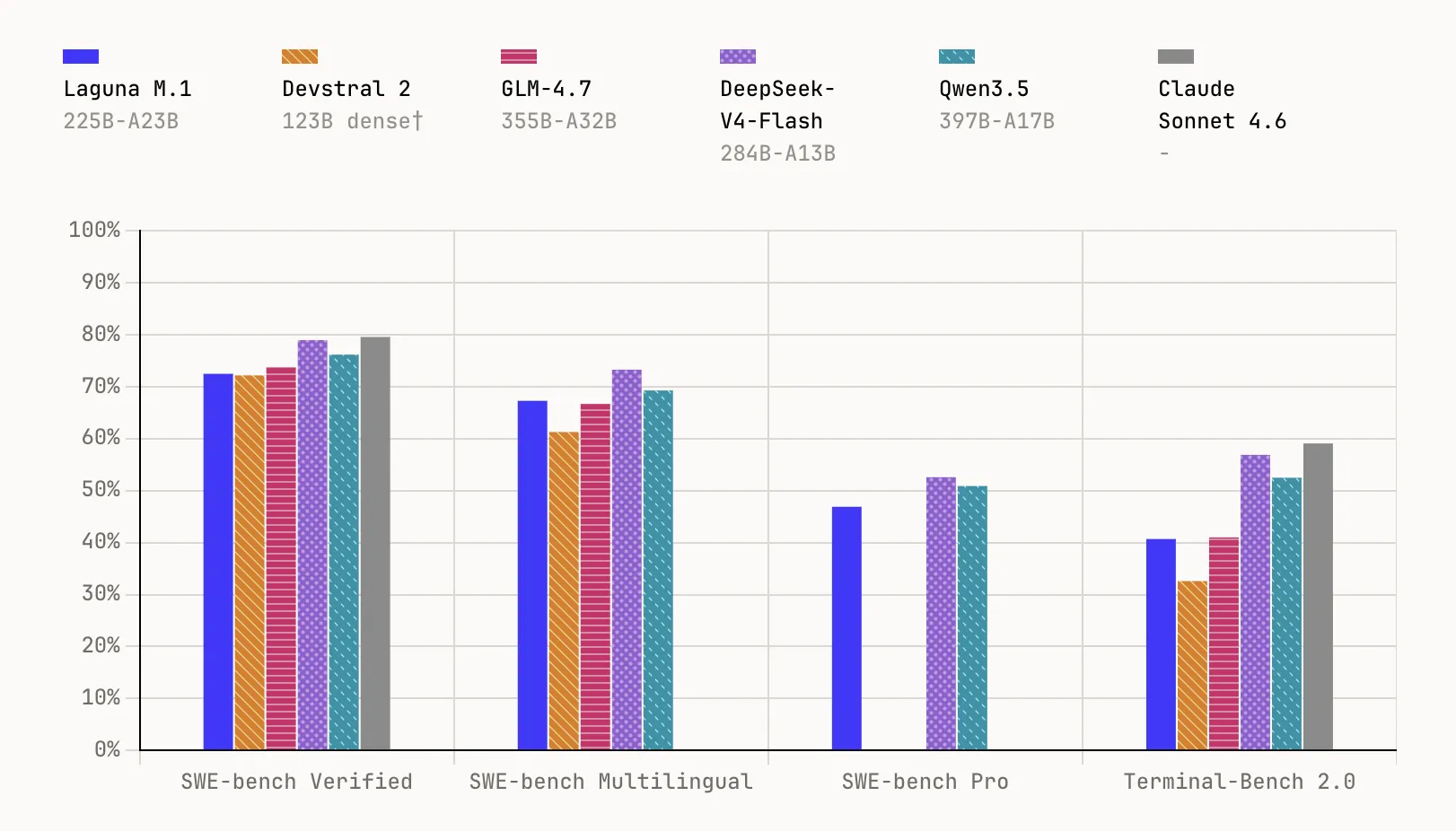
Laguna M.1 is a 225-billion-parameter MoE model with 23 billion active parameters. It was trained entirely from scratch on 30 trillion tokens using 6,144 interconnected NVIDIA Hopper GPUs, with pre-training completed at the end of last year. It serves as the foundation for the entire Laguna lineup. In benchmark testing, it achieved 72.5% on SWE-bench Verified, 67.3% on SWE-bench Multilingual, 46.9% on SWE-bench Pro, and 40.7% on Terminal-Bench 2.0.
Laguna XS.2 is the second-generation MoE model and Poolside’s first open-weight release, incorporating all the insights gained since training M.1. With 33 billion total parameters and just 3 billion active per token, it’s purpose-built for agentic coding and long-horizon tasks on local hardware — compact enough to run on a Mac with 36 GB of RAM via Ollama. It scores 68.2% on SWE-bench Verified, 62.4% on SWE-bench Multilingual, 44.5% on SWE-bench Pro, and 30.1% on Terminal-Bench 2.0. Poolside also plans to release Laguna XS.2-base soon for practitioners interested in fine-tuning.
Architecture: The Design Choices Behind XS.2
XS.2 employs sigmoid gating combined with per-layer rotary scales, supporting a hybrid Sliding Window Attention (SWA) and global attention pattern in a 3:1 ratio across 40 total layers — 30 SWA layers and 10 global attention layers. Sliding Window Attention restricts each token’s focus to a local window of 512 tokens rather than the entire sequence, significantly reducing KV cache memory usage. The global attention layers, placed at a 1-in-4 ratio, maintain long-range contextual dependencies without incurring the full memory cost at every layer. The model also applies FP8 quantization to the KV cache, further cutting memory consumption per token.
Under the hood, XS.2 features 256 experts plus 1 shared expert, supports a context window of 131,072 tokens, and includes native reasoning support — enabling interleaved thinking between tool calls with per-request control over whether reasoning is enabled or disabled.
Training: Three Key Areas Where Poolside Invested Heavily
Poolside’s team trains every model entirely from scratch, leveraging its proprietary data pipeline, custom training framework (Titan), and dedicated agent RL infrastructure. For Laguna, the company focused significant effort on three specific areas.
AutoMixer: Automatically Fine-Tuning the Data Blend. The way data is curated and combined during training has an enormous impact on how well the final model performs. Instead of relying on manual rules of thumb, Poolside created an automixing system that trains a group of around 60 smaller proxy models, each using a different data mixture, and then measures their results across critical capability areas — code, math, STEM, and common sense. Surrogate regression models are then built to estimate how shifting dataset proportions affects downstream benchmarks, producing a learned relationship between data composition and performance that can be directly optimized. This approach draws inspiration from earlier research including Olmix, MDE, and RegMix, customized to fit Poolside’s environment with more detailed data categories.
On the data front, both Laguna models were trained on over 30 trillion tokens. Poolside’s diversity-preserving data curation method — which retains portions of mid- and lower-quality data alongside top-tier material to prevent STEM-heavy bias — delivers roughly 2× more unique tokens compared to precision-focused approaches, with this advantage holding steady even at longer training durations. A separate deduplication study also revealed that global deduplication tends to disproportionately discard high-quality data, which guided how the team configured its pipeline. Synthetic data makes up about 13% of the final training mix in Laguna XS.2, with the Laguna series consuming roughly 4.4T+ synthetic tokens in total.
Muon Optimizer. Rather than AdamW — the go-to optimizer for most large model training — Poolside adopted a distributed version of the Muon optimizer across all training stages for both models. In early pre-training experiments, the research team matched the training loss of an AdamW baseline in roughly 15% fewer steps, with substantial absolute gains on the final model’s evaluations, and achieved learning rate transfer across different model scales. An added advantage: Muon maintains just one state per parameter instead of two, cutting memory usage for both training and checkpoint storage. During pre-training of Laguna M.1, the optimizer’s overhead accounted for less than 1% of each training step’s time.
Poolside also performs periodic hash checks on model weights across training replicas to detect silent data corruption (SDC) caused by faulty GPUs — particularly errors in arithmetic logic and pipeline registers, which unlike DRAM and SRAM are not protected by ECC.
Async On-Policy Agent RL. This is arguably the most complex component of the Laguna training stack. Poolside engineered a fully asynchronous online RL system where actor processes fetch tasks from a dataset, launch sandboxed containers, and run the production agent binary against each task using the freshly deployed model. The resulting trajectories are scored, filtered, and stored in Iceberg tables, while the trainer continuously ingests these records and generates the next checkpoint — inference and training operating asynchronously in parallel, with throughput balanced to manage off-policy staleness.
Key Takeaways
- Poolside releases its first open-weight model: Laguna XS.2 is a 33B total parameter MoE model with only 3B activated parameters per token, available under an Apache 2.0 license — compact enough to
- Ollama enables local execution on a Mac with 36GB of RAM.
- Impressive benchmark results at smaller scale: Laguna XS.2 achieves 68.2% on SWE-bench Verified and 44.5% on SWE-bench Professional. The larger variant, Laguna M.1 (225B total, 23B active parameters), reaches 72.5% and 46.9% respectively. Both models were trained entirely from scratch using a massive 30-trillion-token dataset.
- Muon optimizer outperforms AdamW by 15% in training efficiency: Poolside replaced the standard AdamW optimizer with a distributed version of the Muon optimizer. This change allowed the team to reach the same training loss in about 15% fewer steps while also reducing memory usage—requiring just one state per parameter instead of two.
- Automixer automates data mixture through learned optimization: Rather than manually crafting data recipes, Poolside employs a swarm of approximately 60 proxy models trained on various data distributions. Surrogate regressors analyze these trials to optimize dataset proportions. Notably, synthetic data accounts for roughly 13% of Laguna XS.2’s final training mix, drawn from over 4.4 trillion generated tokens.
- Fully asynchronous agent RL with GPUDirect RDMA weight transfer: Poolside’s RL framework runs inference and training concurrently. It transfers hundreds of gigabytes of BF16 weights between nodes in under five seconds using GPUDirect RDMA. This is powered by a token-in, token-out actor architecture and stabilized via the CISPO algorithm for consistent off-policy training.
Explore the Model Weights and Technical Details. Also, feel free to follow us on Twitter, and don’t forget to join our 130k+ ML SubReddit and subscribe to our Newsletter. And if you’re on Telegram, you can join us there as well!
Interested in partnering with us to promote your GitHub Repository, Hugging Face Page, Product Launch, Webinar, and more? Get in touch with us today!