



Key Insights
- Gradient is an AI infrastructure platform constructing an open, distributed various to centralized AI labs and knowledge facilities by harnessing a world mesh of idle, heterogeneous client gadgets to allow an Open Intelligence Stack (OIS).
- Echo-2 decouples inference from coaching utilizing a dual-swarm structure that separates latency-sensitive mannequin sampling on client “Actors” from high-throughput coverage updates on centralized “Learners.”
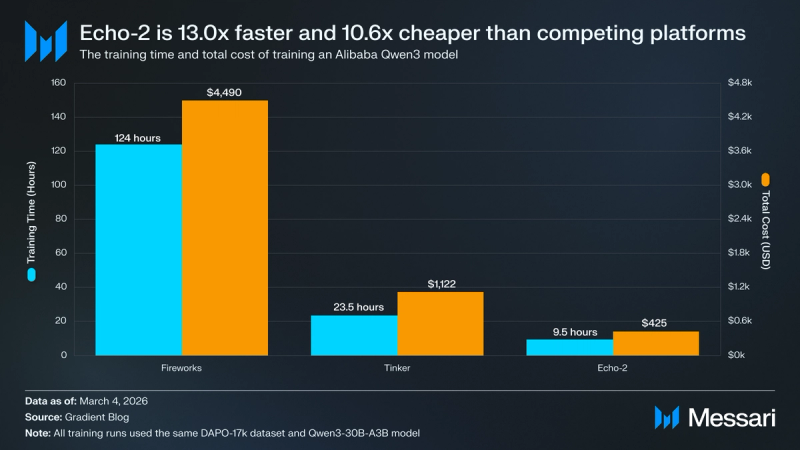
- Throughout preliminary benchmark testing, Echo-2 achieved a ten.6x drop in coaching prices, lowering whole post-training bills from $4,490 on a industrial cloud platform to simply $425, whereas concurrently growing coaching velocity by 13.0x.
- In comparative benchmark testing throughout 5 math reasoning datasets, Echo-2 achieved a imply reward rating of 35.75 on a Qwen3-8B mannequin, barely outperforming ByteDance’s verl framework’s 35.30 imply rating. This analysis demonstrated that Echo-2 maintains full algorithmic constancy whereas lowering cumulative {hardware} prices by 33–36% in comparison with costly knowledge heart clusters.
Primer
Gradient is an AI analysis and growth (R&D) lab creating open, distributed infrastructure as an alternative choice to at the moment’s centralized AI labs. Not like conventional AI frameworks that rely totally on costly, closed knowledge facilities, Gradient harnesses a world mesh of idle, heterogeneous gadgets, together with datacenters, gaming GPUs, Apple Silicon, amongst different gadgets, to execute collaborative workloads. This method unlocks latent compute globally, considerably decreasing the price of coaching and deploying massive language fashions (LLMs). Gradient’s mission is to democratize entry to AI, guaranteeing that customers aren’t simply customers, however energetic creators and homeowners of sovereign, privacy-preserving intelligence.
The platform’s basis is constructed on the Open Intelligence Stack (OIS), an working system and runtime for distributed AI fashions. A core part enabling that is Parallax, a distributed inference engine that shards and routes fashions throughout varied {hardware} environments to ship high-throughput, low-latency inference. One other foundational pillar is Echo, a distributed reinforcement studying (RL) framework that decouples inference from coaching. It employs a dual-swarm structure that successfully decouples the latency-sensitive sampling course of from the high-throughput weight updates. On this ecosystem, a swarm of client “Actors” generates huge quantities of environmental knowledge by way of mannequin sampling, whereas a separate swarm of “Learners” on high-end GPUs asynchronously processes these updates. This drastically reduces post-training prices whereas guaranteeing the coaching course of stays resilient to node downtime.
Lattica, a common peer-to-peer (P2P) knowledge transmission protocol, powers these parts by dealing with NAT traversal, peer discovery, and adaptive routing to securely transfer mannequin weights and execution directions throughout the open net.
Web site / X / Github / Discord / LinkedIn
The Open Intelligence Stack
The Open Intelligence Stack (OIS) is the foundational structure of Gradient, serving as a distributed working system and runtime for AI fashions. Not like conventional AI frameworks that depend on closed, centralized knowledge facilities, the OIS permits a world mesh of machines, starting from high-end gaming GPUs to on a regular basis Apple Silicon gadgets, to collaboratively execute advanced AI workloads.
Present AI R&D is constrained by centralized forces that pose vital dangers to the way forward for AI and society at massive:
- Infrastructure Obstacles: Superior fashions are largely confined to specialised knowledge facilities and costly, enterprise-grade GPUs, making private and sovereign AI methods practically unattainable for the typical consumer.
- Useful resource Inefficiencies: Centralized methods are combating astronomical capital necessities for semiconductors and power calls for that energy grids can not maintain.
- Monopolization: Just a few AI labs and hyperscalers management entry to state-of-the-art (SOTA) fashions, posing dangers of monopolistic management, privateness infringement, and systemic bias.
The Open Intelligence Stack solves these challenges by redefining mannequin inference and coaching as a world, collaborative course of. As an alternative of relying solely on H100 clusters, the OIS unlocks the world’s latent compute and stitches it right into a verifiable, distributed execution engine. This structure ensures that AI is a collective motion the place the group owns the infrastructure, not only a centralized company.
The OIS operates by three foundational primitives that coordinate hundreds of parallel computations throughout unmanaged networks:
- Lattica (Communication): The common peer-to-peer knowledge movement engine. It acts because the “connective tissue” for the stack, dealing with NAT traversal and peer discovery to show remoted machines right into a globally addressable mesh.
- Parallax (Compute): A distributed inference engine and “Sovereign AI OS”. It permits massive basis fashions to be sharded and executed throughout heterogeneous gadgets, permitting on a regular basis {hardware} to run trillion-class fashions that will in any other case be out of attain.
- Echo (Orchestration): A distributed reinforcement studying (RL) framework that decouples inference from coaching. By offloading the compute-heavy sampling section to a swarm of client gadgets, Echo reduces coaching prices by as much as 10.6x in comparison with conventional cloud baselines.
Echo
Echo is a distributed reinforcement studying (RL) framework designed to resolve the bodily limitations of coaching massive language fashions (LLMs) throughout geographically dispersed {hardware}. To know Echo’s significance, we should distinguish between the 2 major phases of mannequin growth:
- Pre-training: The preliminary, compute-intensive section the place a mannequin learns normal patterns and information from huge datasets to create a “base model.”
- Submit-training: The refinement section, the place the mannequin is taught to observe directions, keep away from dangerous outputs, and excel at particular duties.
Whereas pre-training builds uncooked intelligence, post-training transforms a base mannequin right into a useful, consumer-ready product.
Conventional RL coaching is ill-suited for distributed environments as a result of it depends on a synchronous, serial loop. In a normal knowledge heart, GPUs alternate between sampling (producing responses) and coaching (updating gradients). This “stop-and-start” method causes vital {hardware} idling. When tried over the general public web, excessive latency makes this serial method virtually unattainable; nodes spend the overwhelming majority of their time ready for weight updates moderately than performing computation.
Twin-Swarm Structure
Echo essentially alters the economics of RL by decoupling the compute-intensive rollout section, the place the mannequin generates a response and receives a reward, or a numerical rating based mostly on how properly it adopted directions, from the training section, the place the system calculates gradients, that are mathematical directions for enchancment, to replace the mannequin’s weights, the interior insurance policies that decide its habits.:
- The Inference Swarm: A fleet of low-cost, consumer-grade GPUs (Edge Hosts) that carry out the “sampling”. They generate thousands and thousands of trajectories and atmosphere knowledge wanted for the mannequin to be taught.
- The Coaching Swarm: A secure cluster of high-performance GPUs (e.g., A100 or H100) that performs the precise coverage optimization and gradient updates.
Decoupling permits every swarm to scale independently based mostly on demand. This allows analysis groups to run a excessive velocity of experiments at a fraction of the price of centralized suppliers, decreasing the barrier to entry for high-performance RL.
Principled Synchronization
Echo makes use of two distinct synchronization protocols that customers can toggle based mostly on their wants:
- Sequential Mechanism (Most Correct): Prioritizes mathematical precision by requiring the Coaching Swarm to manually “pull” knowledge from the inference nodes. Earlier than offering a response, every inference node should confirm and replace its native mannequin weights to match the coach precisely. Whereas this introduces a quick ready interval, it mirrors the strict reliability of conventional, centralized coaching environments and minimizes the chance of statistical errors.
- Asynchronous Mechanism (Most Environment friendly): Focuses on maximizing the whole quantity of labor processed by the community. Inference nodes repeatedly “push” responses right into a shared “Rollout buffer”, permitting the Coaching Swarm to attract from this pool and carry out updates with out pausing to attend for the community.
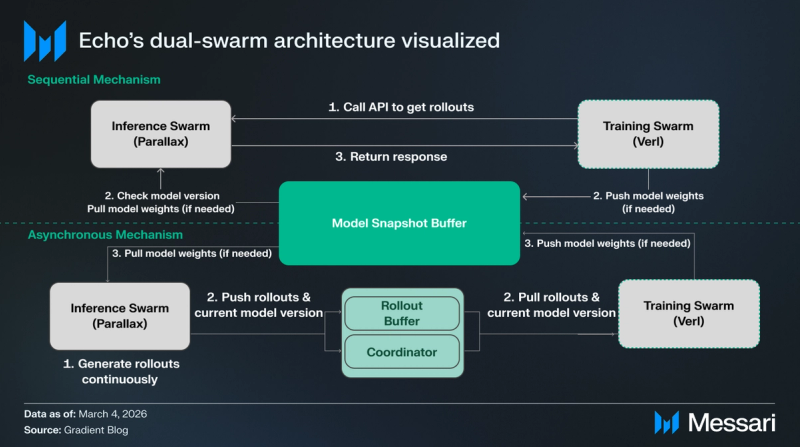
The Mannequin Snapshot Buffer acts because the central repository for the mannequin’s weights, whereas the Inference and Coaching Swarms work together with it in a different way relying on the chosen mechanism. Within the sequential circulate, the Coaching Swarm manually “calls” for knowledge, forcing the Inference Swarm to tug the most recent weights earlier than returning a response, whereas the asynchronous route permits for steady knowledge era and “pushing” to a Rollout Buffer, the place the Coach pulls updates and cycles new weights again to the Snapshot Buffer because the Coordinator manages model skew within the background.
Echo-2
Echo-2 is the second era of Gradient’s RL framework, optimized for large-scale distributed rollout execution over wide-area networks (WAN). It strikes past easy decoupling to deal with WAN constraints as controllable parameters.
The important thing breakthrough of Echo-2 is its skill to deal with coverage staleness. In a decentralized community, the Inference Swarm might generate trajectories utilizing a coverage model that lags behind the present learner state. Echo-2 treats bounded staleness, the degradation of mannequin efficiency when the info it was skilled on now not displays present real-world circumstances, as a user-controlled parameter, sometimes permitting rollouts to lag 3–6 coaching steps behind the learner. This temporal lag permits concurrent rollout era, coverage dissemination, and coaching. Analysis confirms that, for contemporary goals like Group Relative Coverage Optimization (GRPO), average staleness doesn’t degrade ultimate mannequin high quality however permits 100% {hardware} utilization throughout the mesh.
To mitigate the bottleneck of distributing mannequin weights to lots of of actors, Echo-2 employs peer-assisted pipelined broadcast. As an alternative of a “push-to-all” technique that exhausts the learner’s uplink, actors are organized in a tree topology the place they instantly ahead obtained snapshots to friends. This ensures dissemination time scales logarithmically moderately than linearly with fleet dimension.
Echo-2 treats H200 clusters, client 5090s, and different idle cases as a unified logical compute mesh. By using environment friendly Asynchronous RL with bounded staleness, Gradient can orchestrate distributed, unreliable GPUs, {hardware} that’s considerably cheaper as a result of it lacks assured availability. When a node drops out or costs shift, the scheduler mechanically reroutes duties and adjusts the combo. This permits the community to transform uncooked, unstable compute energy into secure, dependable post-training infrastructure.
Three-Aircraft Modular Structure
Echo-2’s three-plane decomposition permits the system to dump the compute-heavy sampling section (Rollout Aircraft) to cheaper, distributed sources whereas sustaining high-performance coverage optimization on a secure cluster (Studying Aircraft).
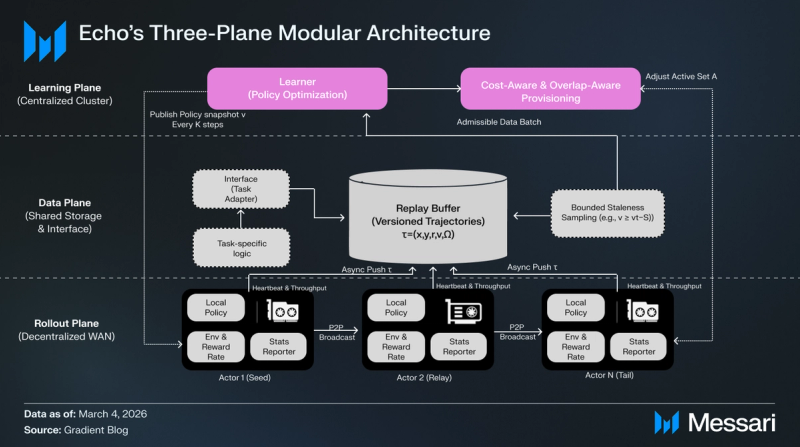
Studying Aircraft
The Studying Aircraft serves because the mind of the system, working on a secure set of high-performance knowledge heart GPUs.
- Coverage Optimization: It consumes trajectory batches from the Information Aircraft to carry out gradient updates utilizing normal algorithms like Proximal Coverage Optimization (PPO) or GRPO.
- Model Administration: Each κ steps, it publishes a brand new, immutable coverage snapshot (v) to the Rollout Aircraft.
- Value-Conscious Provisioning: A scheduler screens the efficient throughput of the rollout fleet and adjusts the energetic employee set to maintain the learner saturated on the lowest doable price.
Information Aircraft
The Information Aircraft acts because the connective tissue, abstracting task-specific logic away from the underlying infrastructure.
- Activity Adapters: They outline the precise prompts, reward features, and the conversion of trajectories into coaching indicators.
- Replay Buffer: This shared storage manages version-tagged trajectories (τ=(x,y,r,v,Ω)).
- Bounded Staleness Sampling: To keep up coaching stability, it filters knowledge, guaranteeing the learner solely consumes rollouts from insurance policies which can be at most S steps previous (e.g., v ≥ vt−S).
Rollout Aircraft
The Rollout Aircraft is a world swarm of heterogeneous, usually “unreliable” consumer-grade {hardware} (e.g., RTX 5090s, Apple Silicon).
- Distributed Technology: Employees generate thousands and thousands of trajectories by working inference ahead passes and reward evaluations.
- Peer-Assisted Pipelined Broadcast: Employees ahead mannequin snapshot chunks to at least one one other instantly upon receipt, enabling them to change to the most recent coverage and roll out quicker.
- Asynchronous Push: Accomplished trajectories are pushed asynchronously to the Information Aircraft’s replay buffer, permitting era and coaching to overlap seamlessly.
Efficiency Analysis
In distributed RL post-training experiments on the AIME24 benchmark, Echo-2 demonstrated that orchestrating a decentralized swarm of consumer-grade RTX 5090s can match the RL high quality of centralized A100 clusters whereas considerably lowering operational prices. Beneath wide-area community constraints, Echo-2 maintained strong efficiency for staleness ranges as much as S≤6, reaching goal high quality at a fraction of the {hardware} rental worth ($0.35/hr for RTX 5090 vs. $3.06/hr for A100).
Value-Effectivity and Velocity
Gradient benchmarked the post-training of a Qwen3-30B mannequin on the DAPO-17k dataset. The workforce ran the identical coaching job throughout Fireworks, Considering Machines’ Tinker, and Echo-2 to straight examine price and coaching time. Echo-2 decreased the whole coaching prices from Fireworks’ $4,490 cloud baseline to simply $425, reaching a ten.6x improve in price effectivity. The coaching job was additionally accomplished 67.8% to 92.3% quicker utilizing Echo-2 (9.5 hours vs 23.5 to 124 hours).
Mannequin High quality and Resilience
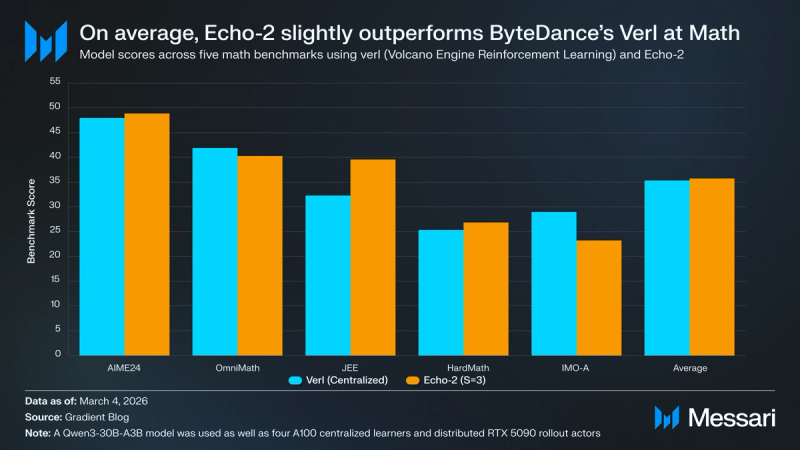
Whereas pace and price are necessary elements, Echo-2’s resilience in dealing with unreliable distributed {hardware} should even be thought of. The Gradient workforce performed inner stress exams utilizing consumer-grade GPUs (RTX 5090s) by way of Parallax to function rollout actors for a centralized 4×A100 learner. Testing on high-stakes mathematical reasoning duties revealed that Echo-2 maintains aggressive scores even beneath wide-area community constraints. On a set of 5 math benchmarks, Echo-2 achieved a imply rating of 35.75, barely exceeding ByteDance’s verl baseline of 35.30. This confirms that the framework can ship enterprise-grade throughput and high quality whereas utilizing {hardware} that’s considerably cheaper due to its lack of assured availability.
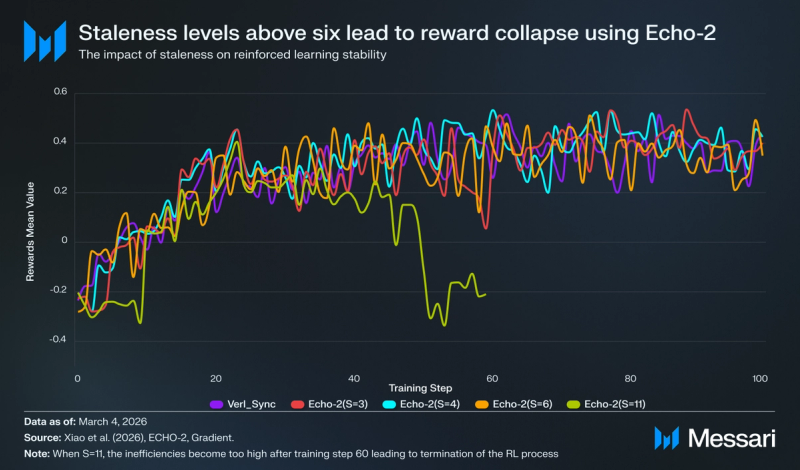
The breakthrough enabling this resilience is the administration of bounded staleness (S). Echo-2 treats staleness as a controllable parameter, sometimes permitting rollouts to lag the learner by 3–6 coaching steps. This temporal slack permits for the era of rollout and the dissemination of coverage to overlap seamlessly with coaching. Whereas average staleness budgets of S=3 to S=6 present strong convergence and near-100% {hardware} utilization, testing signifies a transparent higher certain; at S=11, the system observes full divergence.
Logits
With Echo-2 establishing that analysis velocity is now not capped by infrastructure budgets, Gradient is now productizing this framework by Logits, an RL-as-a-Service (RLaaS) platform.
Logits abstracts away the advanced coordination required for distributed orchestration, providing a streamlined answer for scaling alignment workloads. The platform offers:
- Managed Infrastructure: A turnkey system to deal with the synchronization between centralized learners and distributed rollout fleets.
- International Scale: Direct integration with Parallax to leverage a world mesh of inference capability.
- Mannequin Possession: A shift away from renting closed-source intelligence. Customers can fine-tune open fashions on proprietary knowledge and retain full possession of the ensuing weights.
The Logits waitlist is presently open to school college students and researchers seeking to transition from static analysis to high-velocity, distributed reinforcement studying.
Closing Abstract
Gradient is constructing the Open Intelligence Stack (OIS) to systematically diminish the capital and {hardware} boundaries to AI R&D, exacerbated by centralized infrastructure. Echo-2 neutralizes the latency tax of WANs, reaching as much as a ten.6x discount in post-training prices. By remodeling a fragmented mesh of client {hardware} into resilient AI infrastructure, Gradient permits open-source contributors and smaller labs to iterate at speeds beforehand reserved for giant companies and VC-backed startups.
Because the community transitions from analysis to manufacturing by way of Logits, it establishes the primary onchain platform for RL-as-a-Service (RLaaS). Logits abstracts the complexity of distributed orchestration, permitting researchers to commerce the “closed” gatekeeping of centralized suppliers for the sovereign, resilient compute of a world mesh. This transition positions Gradient as a foundational candidate for a future the place specialised, community-owned AI fashions exchange the capital-intensive, monolithic cloud fashions of at the moment.