



Kubernetes metrics present cluster exercise. You want them to handle Kubernetes clusters, nodes, and purposes. With out them, it additionally makes it more durable to search out issues and enhance efficiency.
This put up will clarify what Kubernetes metrics are, the assorted sorts you ought to be conscious of, the best way to collect them.
What are Kubernetes metrics?
Kubernetes metrics are items of data that point out how properly the objects working in your Kubernetes atmosphere are performing. They’re important as a result of it’s exhausting to search out issues or clear up them earlier than they hurt your apps with out them. They present you the way the cluster is performing.
Varieties of Kubernetes metrics
Kubernetes generates totally different metrics that assist you perceive efficiency at totally different system layers. Listed here are the frequent ones:
Cluster metrics
In Kubernetes, a cluster refers back to the full atmosphere that executes your utility. It has the management aircraft (API server, scheduler, controller supervisor, and many others.), nodes (VMs or bodily servers), and pods/workloads (the containers that function your program).
So cluster metrics are a abstract of metrics from the management aircraft, nodes, and pods/containers. They supply knowledge regarding the well being, efficiency, and useful resource utilization of the entire Kubernetes cluster.
1. Node CPU useful resource utilization
This tells you the way a lot CPU capability the cluster’s nodes are consuming in contrast to what’s out there. You possibly can decide the entire CPU utilization of the cluster by summing the CPU consumption of all of the nodes. Every node has a set quantity of CPU energy. You possibly can inform if nodes are overloaded, balanced, or underused by maintaining a tally of this metric.
2. Node reminiscence utilization
This means how a lot reminiscence (RAM) all of the processes on nodes are utilizing, comparable to kubelet, container runtimes, operating pods, and system companies. Some essential parts of reminiscence utilization embrace:
- Working set reminiscence: Reminiscence actively in use by processes that can not be reclaimed.
- Cache reminiscence: File system cache that may be reclaimed if wanted
- RSS (Resident Set Dimension): Portion of reminiscence occupied in RAM.
Monitoring node reminiscence utilization helps forestall clusters from operating out of assets, which can lead to the termination and elimination of a pod from a node or the crashing of apps.
3. Node disk utilization
When disk use goes over a sure level, like when there’s lower than 10–15% free area, the kubelet kicks out a pod to make room.
Node disk utilization signifies the quantity of area every node in a cluster occupies on the exhausting drive. There could also be no pods left on the node when you run out of disk area.
Node metrics
In Kubernetes clusters, node metrics present a number of data concerning node well being and useful resource utilization.
Monitoring particular person nodes helps troubleshoot points on particular nodes. Metrics like Node CPU Utilization and Node Reminiscence Consumption present how a lot CPU and reminiscence a node is utilizing.
Different node metrics embrace:
1. Disk I/O and out there disk area
Disk I/O measures the learn/write charge on a node’s storage gadgets, whereas Obtainable Disk House reveals the remaining free area on the node’s filesystem.
Excessive disk I/O can decelerate workloads that carry out heavy learn/write duties, inflicting latency. Additionally, operating out of disk area could set off pod eviction or node failures.
2. Community bandwidth utilization
This reveals the information despatched and acquired by a node’s community interfaces per second. Community points can impression communication between pods, nodes, and exterior companies, inflicting delays or timeouts.
Management aircraft metrics
Management aircraft metrics point out the effectiveness of the management aircraft. Only for readability, Kubernetes has two essential components:
- Management aircraft: The mind (decides what ought to run the place)
- Nodes: The employee (really runs your apps and containers).
The management aircraft is the place Kubernetes holds its decision-making and cluster-running capabilities. It schedules your packages, or pods, and displays the cluster’s well being. It additionally offers directions to the employee nodes.
Monitoring management aircraft metrics helps detect points with key companies just like the API server, scheduler, and controllers, making certain cluster reliability and responsiveness.
1. API server request latencies
That is how lengthy the Kubernetes API server takes to answer consumer queries like itemizing nodes, deploying objects, and getting pod data. It reveals how lengthy messages and replies take.
Assume {that a} request to checklist each pod sometimes takes 100 milliseconds. The server could also be struggling a delay because of an overload if there’s a delay of as much as two seconds.
An excessively lengthy API request signifies a sluggish management aircraft, which can make all the cluster much less responsive.
2. Scheduler queue size
Reveals the variety of pods ready to be scheduled to a node. Monitoring queue size helps detect useful resource shortages or scheduler efficiency points early.
The cluster could also be experiencing points with useful resource allocation or setup if the scheduler queue size, which is usually small, unexpectedly will increase to 50+.
The provision and person expertise will be negatively affected by delays in app deployment or workload scalability attributable to a big queue size.
Pod metrics
Pod metrics are the efficiency knowledge about your operating pods. Kubernetes Monitoring helps you catch issues early, know when to scale your apps, and preserve all the things operating easily earlier than customers discover any points.
Except for CPU utilization and reminiscence consumption, listed here are different examples of pod metrics.
1. Pod Restart Rely
This shows what number of occasions a pod’s container restarted as a result of a crash, failure, or useful resource scarcity. If the system restarts usually, apps or assets is perhaps the issue.
2. Pending Pod Rely
This reveals what number of pods are pending. Pending pods are those which might be nonetheless ready to be scheduled to a node. They anticipate the Kubernetes scheduler to find a node that’s good for them.
Pods will be pending for the next causes:
- Inadequate assets out there
- Scheduling issues
- Issues with picture
Run “kubectl get pods — field-selector=status.phase=Pending” to get an inventory of pods to be scheduled.
3. Pod Standing
Pod standing reveals the present state or well being of a pod and signifies if it’s operating easily or dealing with any challenges. Widespread pod statuses embrace:
- Pending: The pod has been accepted by Kubernetes, however its node operation has not but been scheduled.
- Operating: Pod is assigned a node, and at the least one container is operating.
- Succeeded: All containers within the pod accomplished efficiently.
- Failed: A number of containers terminated with an error.
- Unknown: Kubernetes is unable to establish the pod’s situation because of poor communication.
Should you run the command:
kubectl get pods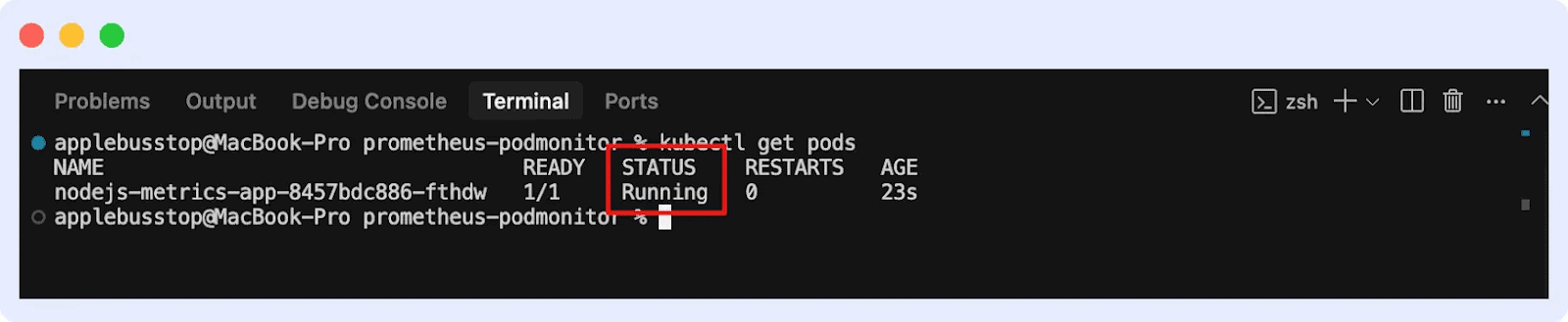
You’ll see the checklist of pods and their standing.
How one can accumulate metrics in Kubernetes
You want Kubernetes monitoring instruments that accumulate, course of, and infrequently retailer data for evaluation as a result of Kubernetes doesn’t retailer all metrics by default.
Metrics server
Metrics Server collects CPU and reminiscence metrics for nodes and pods in Kubernetes. It offers real-time useful resource utilization knowledge for different parts as an alternative of storing it long-term.
Metrics Server collects useful resource utilization knowledge from the kubelet on every node and exposes aggregated metrics by way of the Kubernetes API. It gathers knowledge each 15 seconds to supply close to real-time useful resource utilization.
Right here’s the best way to arrange Metrics Server:
1. Set up the Metric Server utilizing the kubectl command
kubectl apply -f This may create the mandatory Deployment, ServiceAccount, roles, and bindings.
2. Confirm set up by operating the command “kubectl get deployment metrics-server -n kube-system”
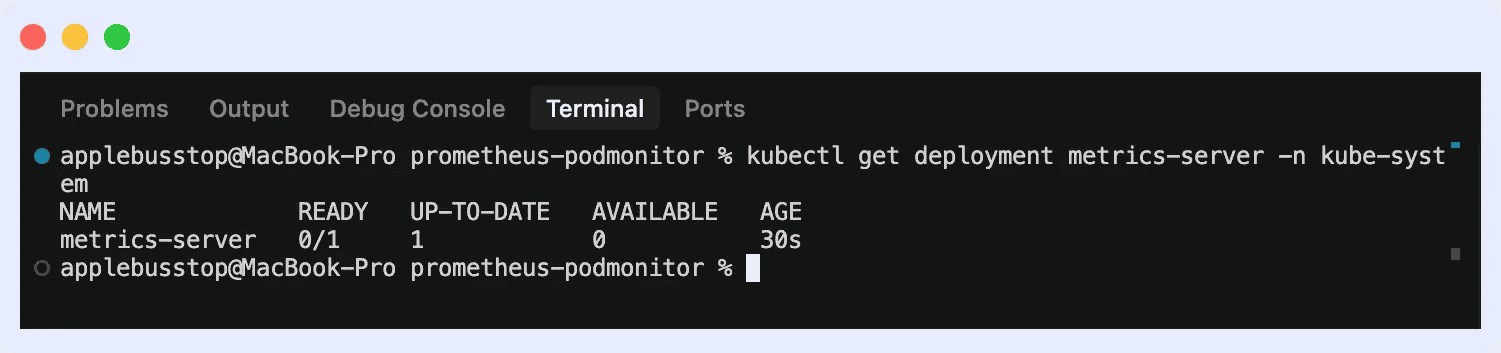
This may guarantee it’s operating with out there pods.
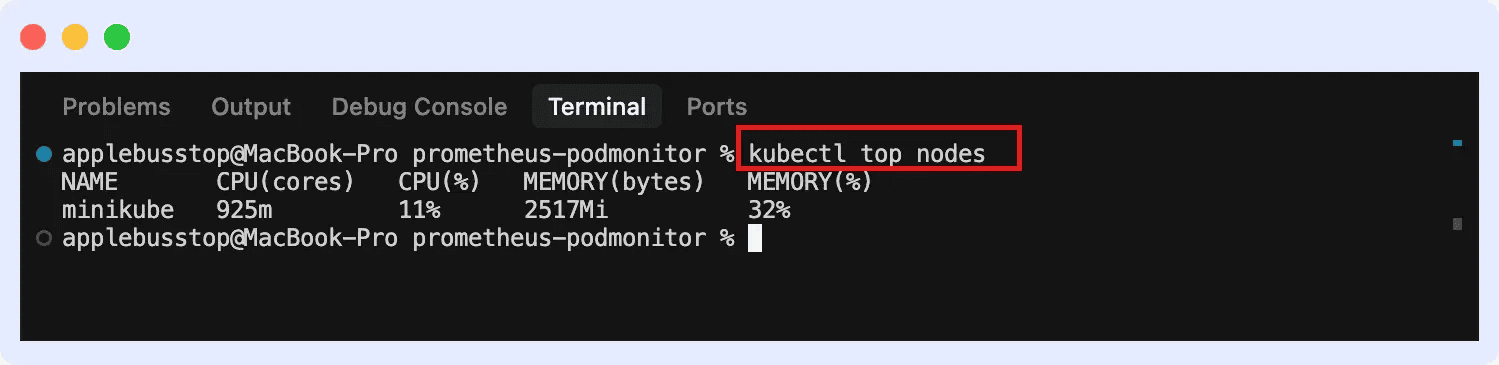
3. Then you’ll be able to view metrics for each nodes and pods.
For nodes:
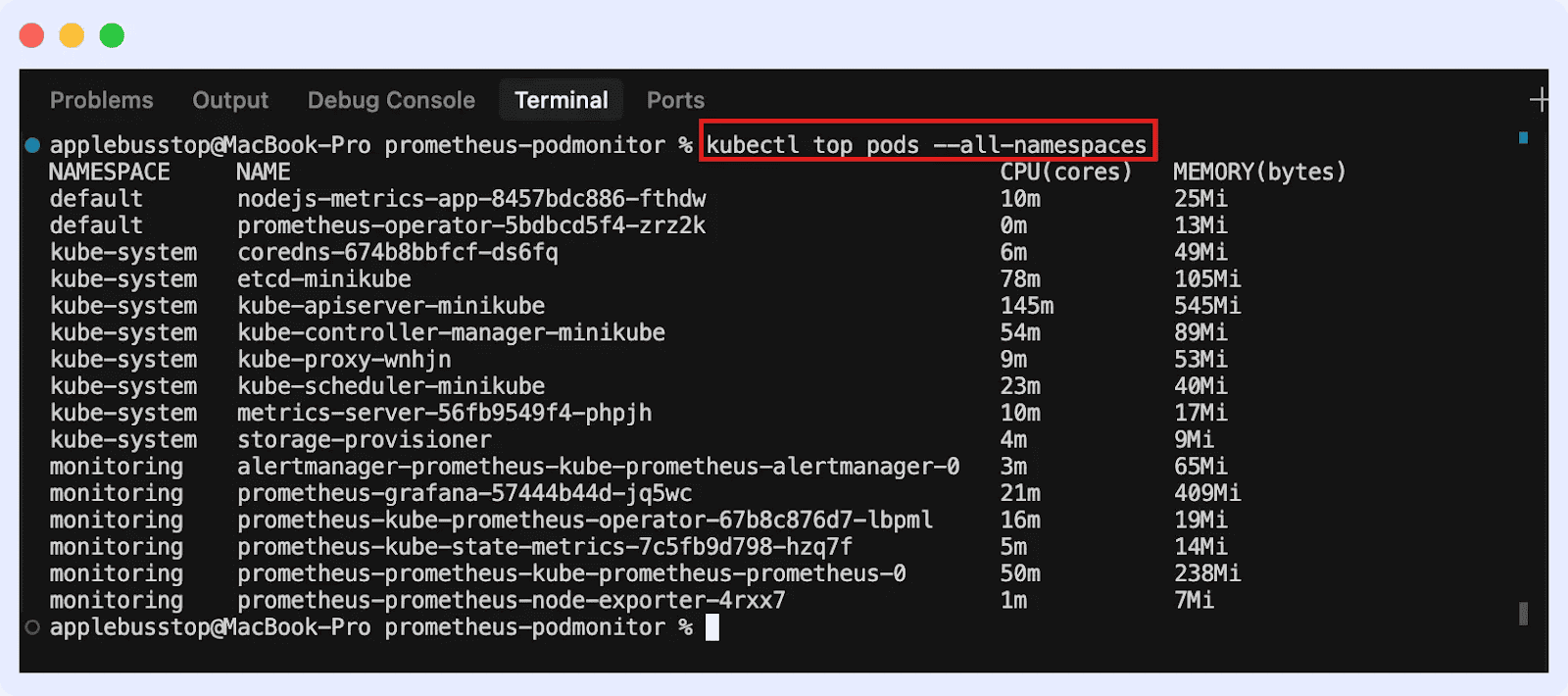
For pods (throughout all namespaces):
cAdvisor
Container Advisor, or cAdvisor, gathers knowledge on useful resource consumption in actual time for pods and containers.
Since cAdvisor is embedded throughout the kubelet, it mechanically collects container-level knowledge on each node. The Kubelet’s endpoint offers metrics that could be used with Prometheus to create dashboards and analyze knowledge.
Kube-State-Metrics
This instrument displays Kubernetes nodes, namespaces, deployments, and pods. It tracks cluster state, configuration, and well being, enabling monitoring methods to gather metrics for visualization, alerting, and evaluation.
Right here’s the best way to set up it:
1. Set up through Helm
First, add the Prometheus group Assist repo:
helm repo add prometheus-community
helm repo replace
Set up Kube-State-Metrics in your cluster:
helm set up kube-state-metrics prometheus-community/kube-state-metrics
This creates the mandatory deployments, service accounts, and permissions mechanically.
2. Set up manually utilizing YAML manifests
Apply the official Kube-State-Metrics manifests offered within the GitHub repo:
kubectl apply -f
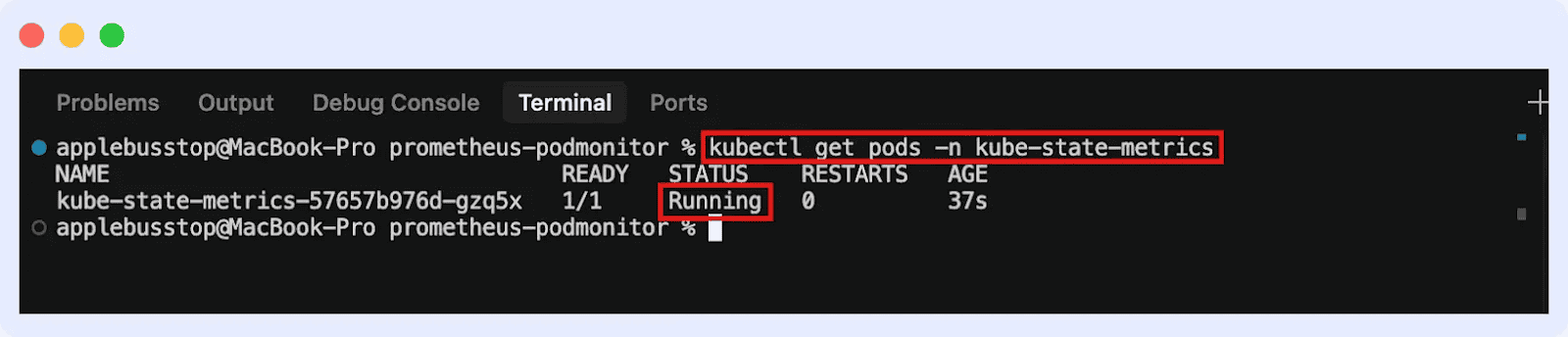
This may deploy Kube-State-Metrics in your cluster. You possibly can go forward to verify if it’s operating:
Conclusion
Metrics assist you verify pods, nodes, and clusters. They let you regulate the well being and situation of workloads to search out issues early and ensure apps work properly.
To grasp the context of what issues metrics can reveal, discover our weblog on Kubernetes Troubleshooting Methods.
Conclusion
Metrics assist you verify pods, nodes, and clusters. They let you regulate the well being and situation of workloads to search out issues early and ensure apps work properly.
To grasp the context of what issues metrics can reveal, discover our weblog on Kubernetes Troubleshooting Methods.