



As AI adoption accelerates throughout industries, organizations face a essential bottleneck that’s usually missed till it turns into a severe impediment: reliably managing and distributing giant mannequin weight recordsdata at scale. A mannequin’s weights function the central artifact that bridges each coaching and inference pipelines — but the infrastructure surrounding this artifact is steadily an afterthought.
This text addresses the operational challenges of managing AI mannequin artifacts at enterprise scale, and introduces a cloud-native answer that brings software program supply greatest practices – versioning, immutability, and GitOps, to the world of huge mannequin recordsdata.
The hole no person talks about — till it breaks manufacturing
The cloud native hole: Most current ML mannequin storage approaches weren’t designed with Kubernetes-native supply in thoughts, leaving a essential hole between how software program artifacts are managed and the way mannequin artifacts are managed. Inside the CNCF ecosystem, tasks corresponding to ModelPack, ORAS, Harbor, and Dragonfly are exploring complementary approaches to managing and distributing giant artifacts.
Immediately, enterprises function AI infrastructure on Kubernetes but their mannequin artifact administration lags behind. Software program containers are pulled from OCI registries with full versioning, safety scanning, and rollback help. Mannequin weights, against this, are sometimes downloaded through advert hoc scripts, copied manually between storage buckets, or distributed by means of unsecured shared filesystems. This hole creates deployment fragility, safety dangers, and operational overhead at scale.
When your mannequin weighs greater than your whole app
Fashionable basis fashions aren’t small. A single mannequin checkpoint can vary from tens of gigabytes to a number of terabytes. For reference, a quantized LLaMA-3 70B mannequin weighs roughly 140 GB, whereas frontier multimodal fashions can simply exceed 1 TB. These aren’t recordsdata you version-control with commonplace Git — they demand devoted storage methods, environment friendly switch protocols, and cautious entry management.
The core challenges are: storage at scale, distribution pace, and reproducibility. Groups have to retailer a number of mannequin variations, quickly distribute them to GPU inference nodes throughout areas, and assure that any deployment may be traced again to a precise, immutable artifact.
Three paths ahead — and why none of them are sufficient
| Git LFS (Hugging Face Hub) | Object Storage (S3, MinIO) | Distributed Filesystem (NFS, CephFS) | |
| Professionals | Native model management (branches, tags, commits, historical past). | Customary providing from cloud suppliers. Native help in engines like vLLM/SGLang. | POSIX appropriate. Low integration price. |
| Cons | Poor protocol adaptation for cloud-native environments. Inherits Git’s transport inefficiencies, lacks optimizations for big file distribution. | Lacks structured metadata. Weak model administration capabilities. | Lacks structured metadata. Weak model administration capabilities. Excessive operational complexity for distributed filesystems. |
The strategy described right here treats AI mannequin weights as first-class OCI (Open Container Initiative) artifacts, packaging them in the identical container registries used for utility photos. This permits mannequin supply to leverage the total ecosystem of container tooling: safety scanning, signed provenance, GitOps-driven deployment, and Kubernetes-native pulling.
What If we shipped fashions the identical means we ship code?
Within the cloud-native period, builders have lengthy established a mature and environment friendly paradigm for software program supply.
The software program supply:
- Develop: Builders commit code to a Git repository, handle code adjustments by means of branches, and outline variations utilizing tags at key milestones.
- Construct: CI/CD pipelines compile and take a look at, packaging the output into an immutable Container Picture.
- Handle and ship: Photographs are saved in a Container Registry. Provide chain safety (scanning/signing), RBAC, and P2P distribution guarantee secure supply.
- Deploy: DevOps engineers use declarative Kubernetes YAML to outline the specified state. The Container’s lifecycle is managed by Kubernetes.
The cloud native AI mannequin supply:
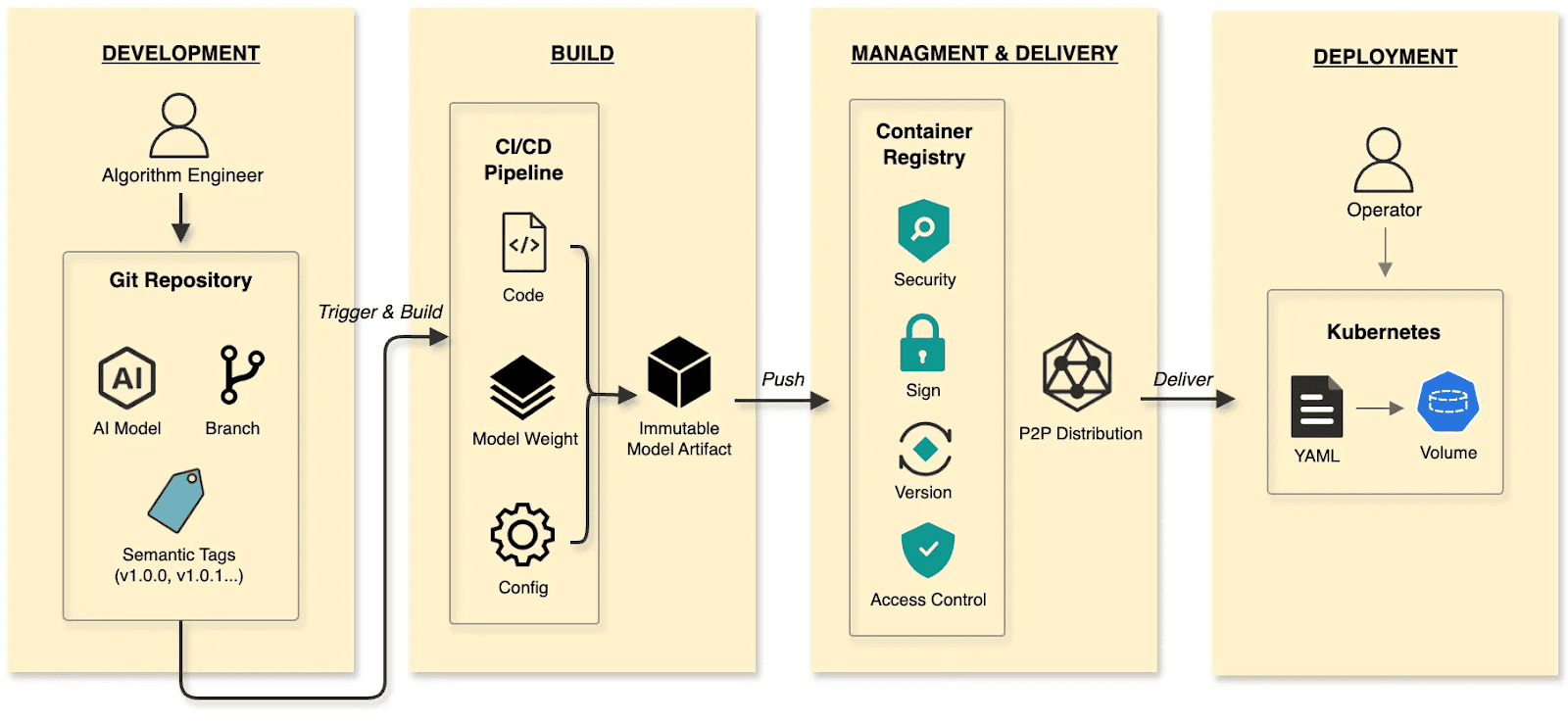
- Develop: Algorithm engineers push weights and configs to the Hugging Face Hub, treating it because the Git Repository.
- Construct: CI/CD pipelines package deal weights, runtime configurations, and metadata into an immutable Mannequin Artifact.
- Handle and ship: The Mannequin Artifact is managed by an Artifact Registry, reusing the prevailing container infrastructure and toolchain.
- Deploy: Engineers use Kubernetes OCI Volumes or a Mannequin CSI Driver. Fashions are mounted into the inference Container as Volumes through declarative semantics, decoupling the AI mannequin from the inference engine (vLLM, SGLang, and so on.).
By making use of software program supply paradigms and provide chain considering to mannequin lifecycle administration, we constructed a granular, environment friendly system that resolves the challenges of managing and distributing AI fashions in manufacturing.
Strolling the pipeline: A construct story in 4 steps
Construct
modctl is a CLI software designed to package deal AI fashions into OCI artifacts. It standardizes versioning, storage, distribution and deployment, guaranteeing integration with the cloud-native ecosystem.

Step 1: Auto-generate Modelfile
Run the next within the mannequin listing to generate a definition file.
$ modctl modelfile generate .Step 2: Customise Modelfile
You may also customise the content material of the Modelfile.
# Mannequin identify (string), corresponding to llama3-8b-instruct, gpt2-xl, qwen2-vl-72b-instruct, and so on.
NAME qwen2.5-0.5b
# Mannequin structure (string), corresponding to transformer, cnn, rnn, and so on.
ARCH transformer
# Mannequin household (string), corresponding to llama3, gpt2, qwen2, and so on.
FAMILY qwen2
# Mannequin format (string), corresponding to onnx, tensorflow, pytorch, and so on.
FORMAT safetensors
# Specify mannequin configuration file, help glob path sample.
CONFIG config.json
# Specify mannequin configuration file, help glob path sample.
CONFIG generation_config.json
# Mannequin weight, help glob path sample.
MODEL *.safetensors
# Specify code, help glob path sample.
CODE *.pyStep 3: Login to Artifact Registry (Harbor)
$ modctl login -u username -p password harbor.registry.comStep 4: Construct OCI Artifact
$ modctl construct -t harbor.registry.com/fashions/qwen2.5-0.5b:v1 -f Modelfile .A Mannequin Manifest is generated after the construct. Descriptive info corresponding to ARCH, FAMILY, and FORMAT is saved in a file with the media kind utility/vnd.cncf.mannequin.config.v1+json.
{
"schemaVersion": 2,
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"artifactType": "application/vnd.cncf.model.manifest.v1+json",
"config": {
"mediaType": "application/vnd.cncf.model.config.v1+json",
"digest": "sha256:d5815835051dd97d800a03f641ed8162877920e734d3d705b698912602b8c763",
"size": 301
},
"layers": [
{
"mediaType": "application/vnd.cncf.model.weight.v1.raw",
"digest": "sha256:3f907c1a03bf20f20355fe449e18ff3f9de2e49570ffb536f1a32f20c7179808",
"size": 4294967296
},
{
"mediaType": "application/vnd.cncf.model.weight.v1.raw",
"digest": "sha256:6d923539c5c208de77146335584252c0b1b81e35c122dd696fe6e04ed03d7411",
"size": 5018536960
},
{
"mediaType": "application/vnd.cncf.model.weight.config.v1.raw",
"digest": "sha256:a5378e569c625f7643952fcab30c74f2a84ece52335c292e630f740ac4694146",
"size": 106
},
{
"mediaType": "application/vnd.cncf.model.weight.code.v1.raw",
"digest": "sha256:15da0921e8d8f25871e95b8b1fac958fc9caf453bad6f48c881b3d76785b9f9d",
"size": 394
},
{
"mediaType": "application/vnd.cncf.model.doc.v1.raw",
"digest": "sha256:5e236ec37438b02c01c83d134203a646cb354766ac294e533a308dd8caa3a11e",
"size": 23040
}
]
}Step 5: Push
$ modctl push harbor.registry.com/fashions/qwen2.5-0.5b:v1Administration
Present AI infrastructure workflows focus closely on mannequin distribution efficiency, usually ignoring mannequin administration requirements. Handbook copying works for experiments, however in large-scale manufacturing, missing unified versioning, metadata specs, and lifecycle administration is poor observe. As the usual cloud-native Artifact Registry, Harbor is ideally fitted to mannequin storage, treating fashions as inference artifacts.
Harbor standardizes AI mannequin administration by means of:
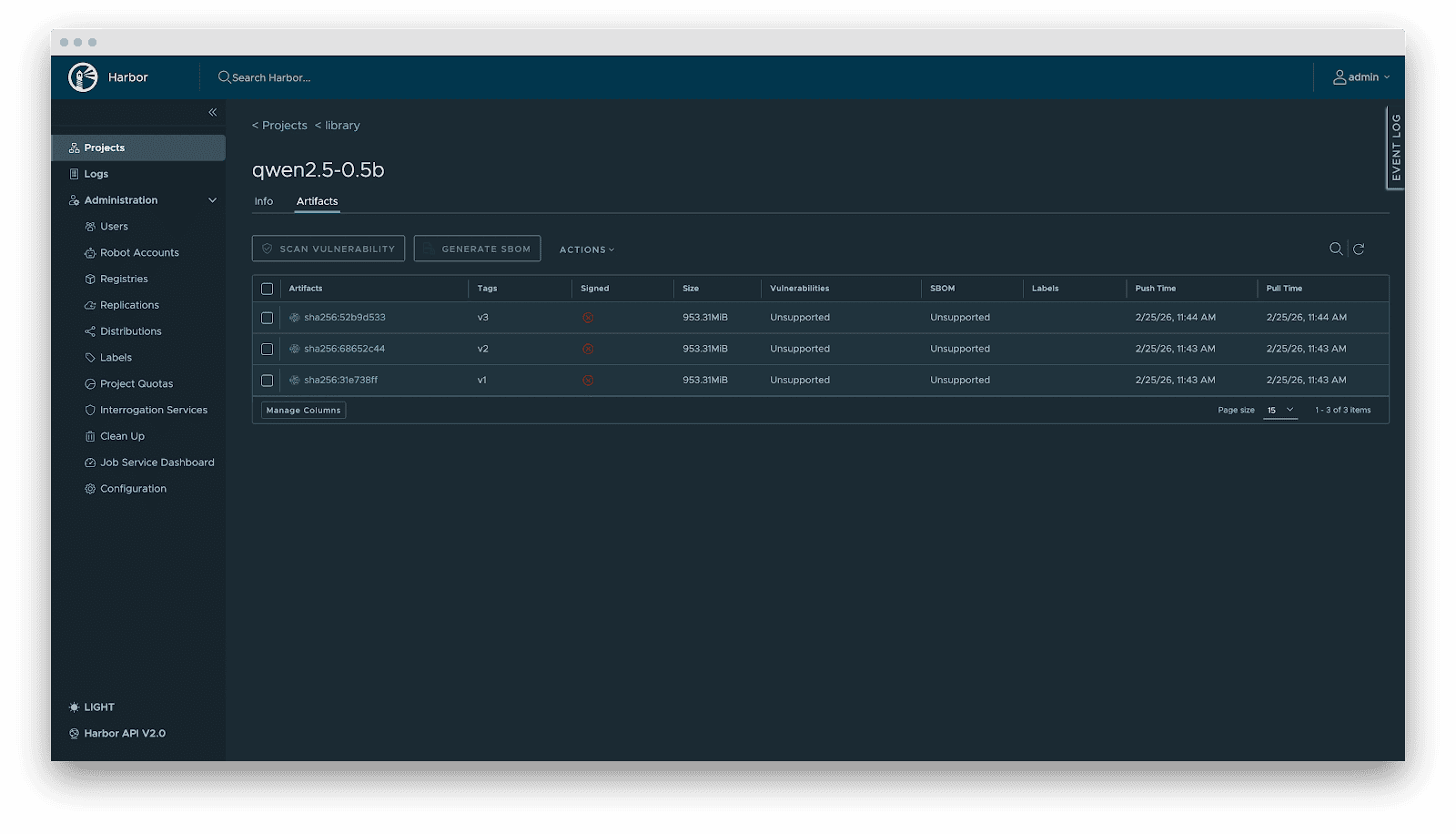
- Versioning: Fashions are OCI Artifacts with immutable Tags and Sha256 Digests. This ensures deterministic inference environments. In the meantime, it visually presents the mannequin’s fundamental attributes, parameter configurations, show info, and the file listing, which not solely reduces the dangers of unknown variations but additionally achieves full transparency of the mannequin.
- RBAC: Positive-grained entry management. Management who can PUSH (e.g., Algorithm Engineers), who can solely PULL (e.g., Inference Providers), and who has administrative privileges.
- Lifecycle administration: Tag retention insurance policies routinely purge non-release variations whereas locking energetic variations, balancing storage prices with stability.
- Provide chain safety: Integration with Cosign/Notation for signing. Harbor enforces signature verification earlier than distribution, stopping mannequin poisoning assaults.
- Replication: Automated, incremental synchronization between central and edge registries or active-standby clusters.
- Audit: Complete logging of all artifact operations (pull/push/delete) for safety compliance and traceability.
Supply
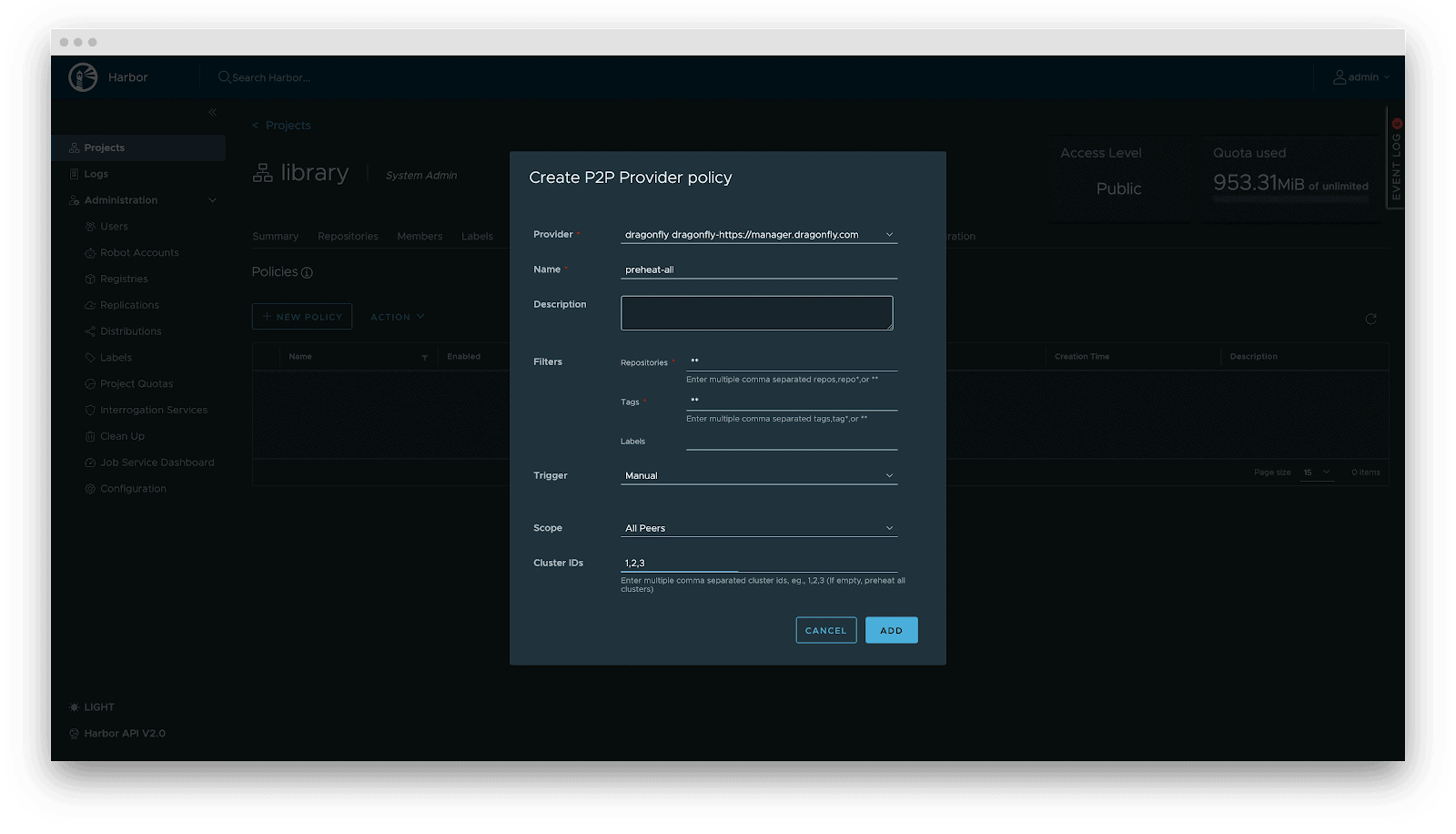
Downloading terabyte-sized mannequin weights instantly from the origin introduces bandwidth bottlenecks. We make the most of Dragonfly for P2P-based distribution, built-in with Harbor for preheating.
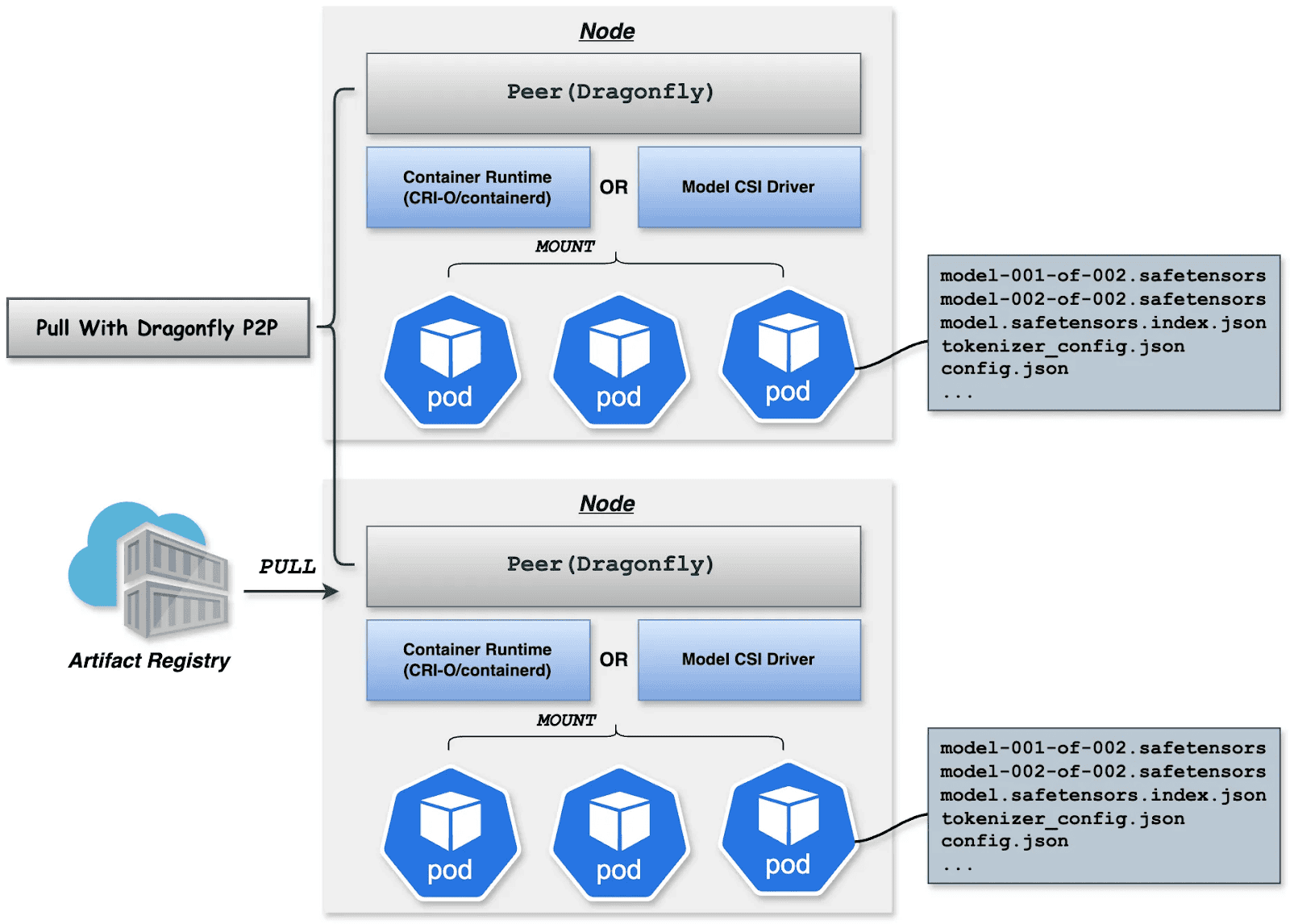
Dragonfly P2P-based distribution
For big-scale distribution situations, Dragonfly has been deeply optimized based mostly on P2P expertise. Taking the instance of 500 nodes downloading a 1TB mannequin, the system distributes the preliminary obtain duties of various layers throughout nodes to maximise downstream bandwidth utilization and keep away from single-point congestion. Mixed with a secondary bandwidth-aware scheduling algorithm, it dynamically adjusts obtain paths to remove community hotspots and long-tail latency. For particular person mannequin weight, Dragonfly splits particular person mannequin weights into items and fetches them concurrently from the origin. This permits streaming-based downloading, permitting customers to share fashions with out ready for the whole file. This answer has been confirmed in high-performance AI clusters, using 70%–80% of every node’s bandwidth and enhancing mannequin deployment effectivity.
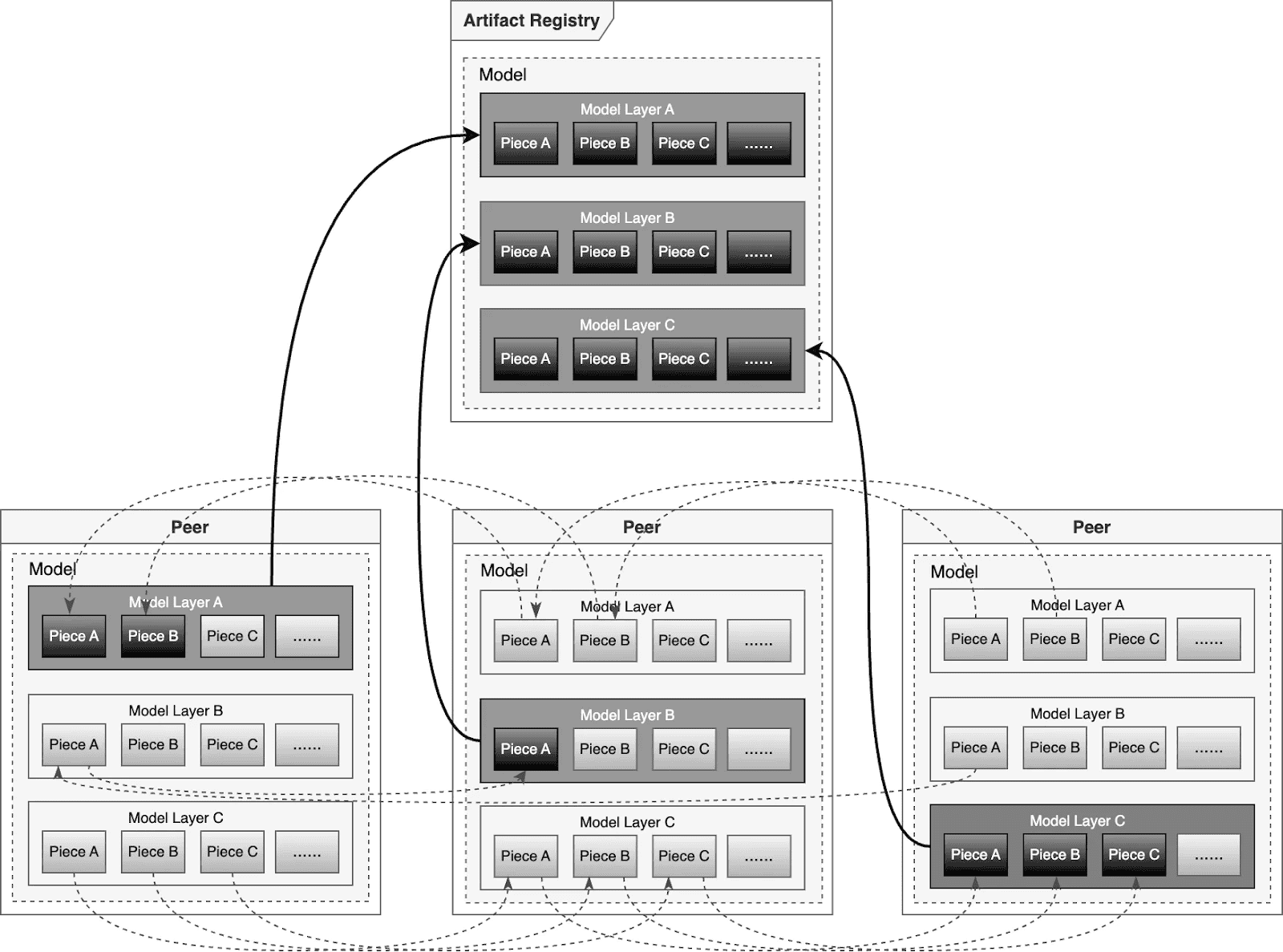
Preheating
For latency-sensitive inference companies, Harbor triggers Dragonfly to distribute and cache knowledge on the right track nodes earlier than service scaling. When the occasion begins, the mannequin masses from the native disk, reaching zero community latency.
Deployment
Deployment focuses on decoupling the Mannequin (Information) from the Inference Engine (Compute). By leveraging Kubernetes declarative primitives, the Engine runs as a Container, whereas the Mannequin is mounted as a Quantity. This native strategy not solely allows a number of Pods on the identical node to share and reuse the mannequin, saving disk area, but additionally leverages the preheating and P2P capabilities of Harbor & Dragonfly to remove the latency of pulling giant mannequin weights, considerably enhancing startup pace.
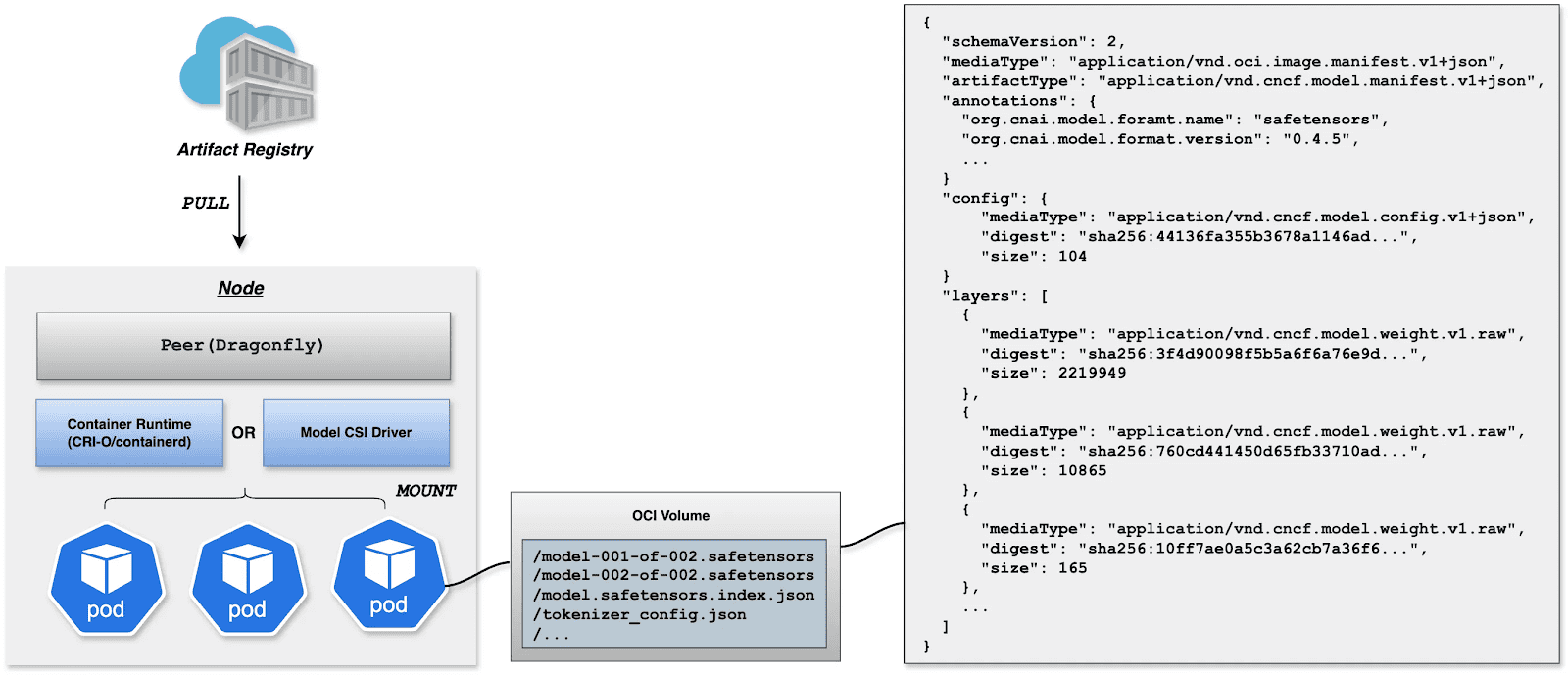
OCI Volumes (Kubernetes 1.31+)
Native help for mounting OCI artifacts as volumes through CRI-O/containerd. This characteristic was launched as alpha in Kubernetes 1.31 (requires enabling the ImageVolume characteristic gate) and promoted to beta in Kubernetes 1.33 (enabled by default, no characteristic gate configuration wanted). CRI-O particularly enhances this for LLMs by avoiding decompression overhead at mount time by storing layers uncompressed, leading to superior efficiency when mounting giant mannequin recordsdata.
Step 1: Construct YAML
apiVersion: v1
type: Pod
metadata:
identify: vllm-cpu-inference
labels:
app: vllm
spec:
containers:
- identify: vllm
picture: openeuler/vllm-cpu:newest
command:
- "python3"
- "-m"
- "vllm.entrypoints.openai.api_server"
args:
- "--model"
- "/models"
- "--dtype"
- "float32"
- "--host"
- "0.0.0.0"
- "--port"
- "8000"
- "--max-model-len"
- "1024"
- "--disable-log-requests"
env:
- identify: VLLM_CPU_KVCACHE_SPACE
worth: "1"
- identify: VLLM_WORKER_MULTIPROC_METHOD
worth: "spawn"
assets:
requests:
reminiscence: "2Gi"
cpu: "1"
limits:
reminiscence: "16Gi"
cpu: "8"
volumeMounts:
- identify: model-volume
mountPath: /fashions
readOnly: true
ports:
- containerPort: 8000
protocol: TCP
identify: http
livenessProbe:
httpGet:
path: /well being
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /well being
port: 8000
initialDelaySeconds: 30
periodSeconds: 5
volumes:
- identify: model-volume
picture:
reference: ghcr.io/chlins/qwen2.5-0.5b:v1
pullPolicy: IfNotPresent
---
apiVersion: v1
type: Service
metadata:
identify: vllm-service
spec:
selector:
app: vllm
ports:
- port: 8000
targetPort: 8000
protocol: TCP
identify: http
kind: ClusterIPStep 2: Deploy inference Workload
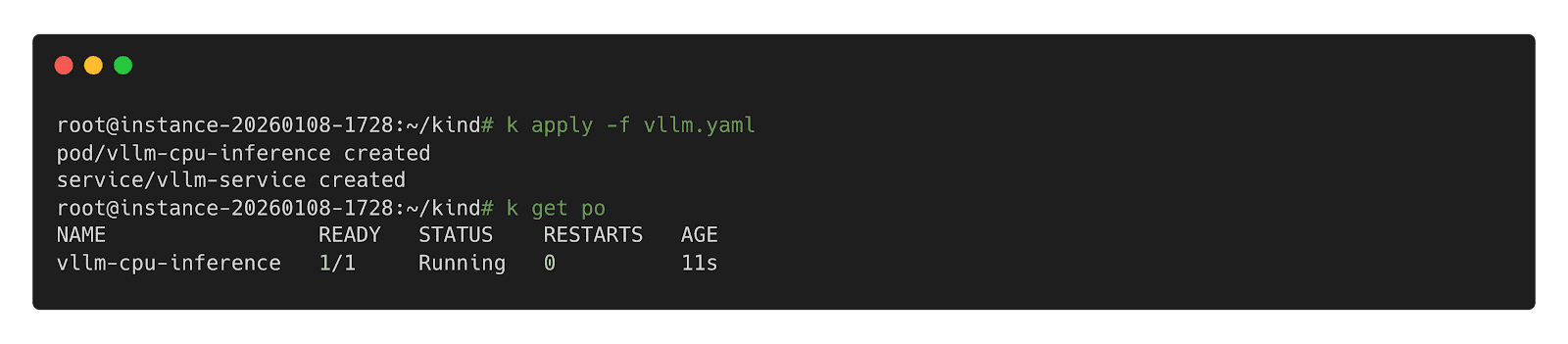
Step 3: Name Inference Workload
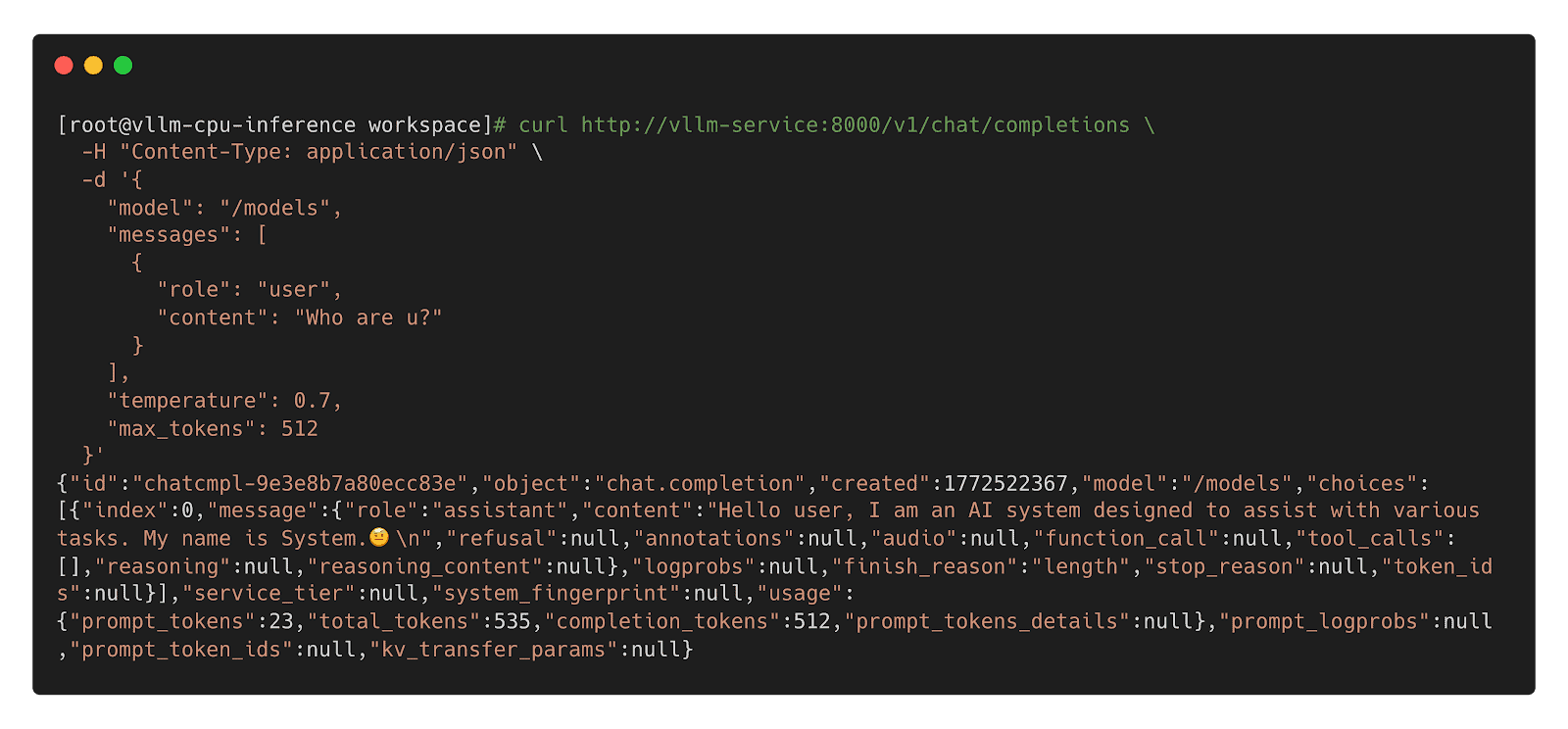
Mannequin CSI Driver
For compatibility with Kubernetes 1.31 and older, we provide the Mannequin CSI Driver as an interim answer to mount and deploy fashions as volumes. As OCI Volumes are slated for GA in Kubernetes 1.36, shifting to native OCI Volumes is advisable for the long run.
Step 1: Construct YAML
apiVersion: v1
type: Pod
metadata:
identify: vllm-cpu-inference
labels:
app: vllm
spec:
containers:
- identify: vllm
picture: openeuler/vllm-cpu:newest
command:
- "python3"
- "-m"
- "vllm.entrypoints.openai.api_server"
args:
- "--model"
- "/models"
- "--dtype"
- "float32"
- "--host"
- "0.0.0.0"
- "--port"
- "8000"
- "--max-model-len"
- "1024"
- "--disable-log-requests"
env:
- identify: VLLM_CPU_KVCACHE_SPACE
worth: "1"
- identify: VLLM_WORKER_MULTIPROC_METHOD
worth: "spawn"
assets:
requests:
reminiscence: "2Gi"
cpu: "1"
limits:
reminiscence: "16Gi"
cpu: "8"
volumeMounts:
- identify: model-volume
mountPath: /fashions
readOnly: true
ports:
- containerPort: 8000
protocol: TCP
identify: http
livenessProbe:
httpGet:
path: /well being
port: 8000
initialDelaySeconds: 60
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /well being
port: 8000
initialDelaySeconds: 30
periodSeconds: 5
volumes:
- identify: model-volume
csi:
driver: mannequin.csi.modelpack.org
volumeAttributes:
mannequin.csi.modelpack.org/reference: ghcr.io/chlins/qwen2.5-0.5b:v1
---
apiVersion: v1
type: Service
metadata:
identify: vllm-service
spec:
selector:
app: vllm
ports:
- port: 8000
targetPort: 8000
protocol: TCP
identify: http
kind: ClusterIPStep 2: Deploy Inference Workload
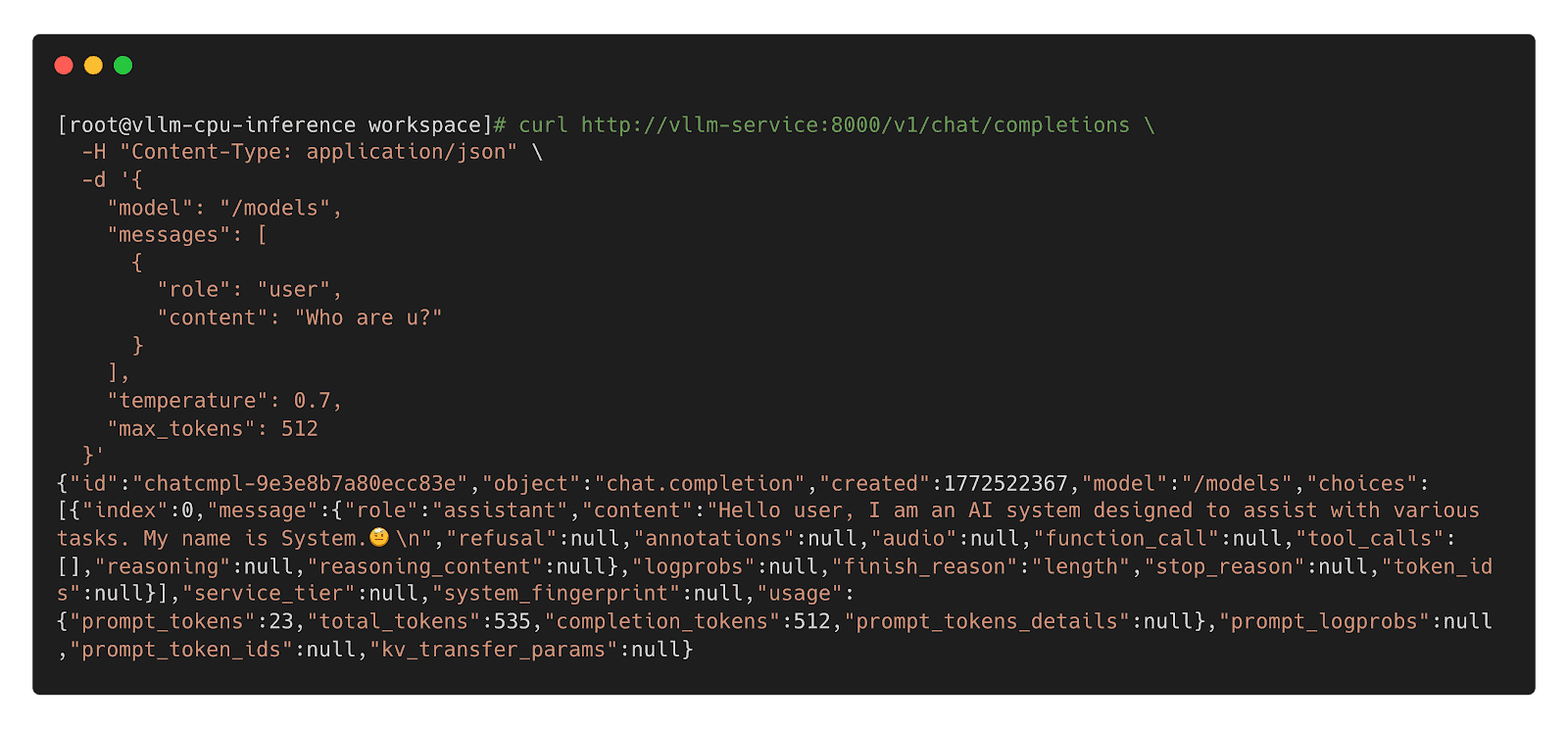
Step 3: Name Inference Workload
- Enhanced Preheating: Enable fashions to be preheated to specified nodes and querying cache distribution throughout nodes for model-aware pod scheduling.
- Dragonfly RDMA Acceleration: Allow Dragonfly to make the most of InfiniBand or RoCE to enhance the pace of distribution.
- Lazy Loading: Implement on-demand downloading of mannequin weights to scale back startup latency.
- containerd Optimization: Improve the OCI Volumes implementation to scale back decompression overhead for big layers.
- Mannequin Safety Scanning: Introduce deep scanning capabilities particularly designed for mannequin weights to detect embedded malicious payloads.