



GR00T N1 is an instance of a vision-language-action mannequin. Supply: NVIDIA
Robotics has historically used modular pipelines. Notion, planning, and management sit in separate programs and join by way of hand-tuned interfaces. This method works for easy, well-defined duties. It struggles when environments change or when robots should comply with versatile directions. Imaginative and prescient-language-action, or VLA, fashions provide a unique path.
Programs equivalent to Determine AI’s Helix, NVIDIA’s GR00T N1, and Google DeepMind’s RT-1, launched final 12 months, mix imaginative and prescient, language understanding, and motor management right into a single mannequin. These programs function end-to-end and act immediately on actual robots.
This shift issues now as a result of latest work reveals sensible, on-device deployments. These can cut back latency, enhance dexterity, and permit quicker process adjustments. VLAs level towards robots that perceive pure directions, perform multi-step duties, and transfer easily with out fragile, hand-built pipelines.
Let’s take a look at how VLAs work, evaluate main approaches, and study {hardware}, deployment, and security issues for business robotics groups.
What are vision-language-action fashions?
Imaginative and prescient-language-action fashions are unified AI programs that mix imaginative and prescient, language understanding, and motion into one end-to-end mannequin. VLAs soak up photos (or video) and language directions, and produce steady motor instructions that drive a robotic’s habits within the bodily world.
This method differs from conventional robotics. Older programs break up notion, planning, and management into separate modules. Engineers join them with hand-built guidelines, which frequently fail in messy and versatile environments.
VLAs construct on vision-language fashions (VLMs) by including motion. They do greater than acknowledge scenes or reply questions. They resolve how a robotic ought to transfer, grasp, and manipulate objects.
By joint coaching throughout imaginative and prescient, semantics, and motor habits, VLAs be taught shared representations that help versatile process execution. This basis leads immediately into the important thing VLA architectures that now drive fast progress in autonomous robotics.

Key architectures drive vision-language-action progress
A number of latest vision-language-action architectures present how this new paradigm strikes from analysis into working robotic programs. Every takes a unique path towards unifying notion, language, and motion.
Helix – Excessive-frequency dexterous management
Helix is a VLA mannequin developed by Determine AI to manage the complete higher physique of its humanoid robots. It targets arms, arms, torso, and fingers at excessive frequency.
Helix makes use of a dual-system design. A big vision-language spine handles high-level reasoning and process understanding. A separate, quick visuomotor coverage converts these inner representations into steady management alerts.
This break up permits Helix to generalize throughout duties whereas nonetheless assembly the real-time calls for of dexterous manipulation in unstructured environments.
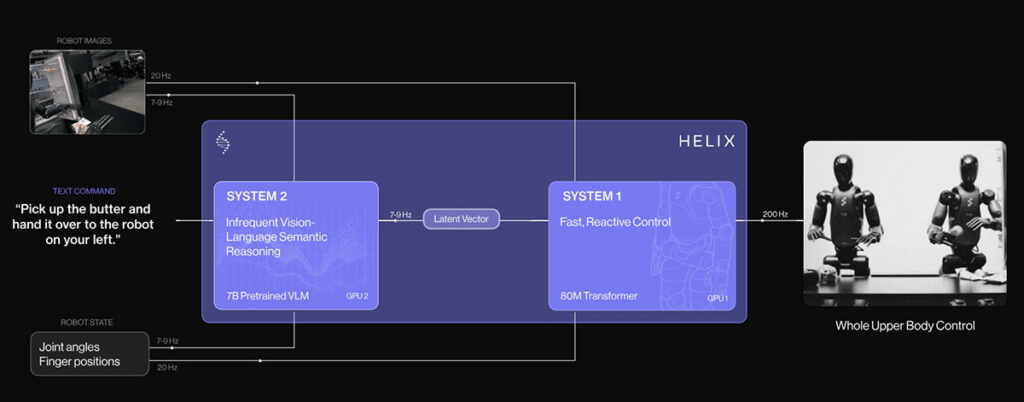
Helix structure. Supply: Determine AI
GR00T N1 – Open, generalist robotics basis mannequin
GR00T N1, launched by NVIDIA, follows a foundation-model method for robotics. It’s skilled offline on a mixture of robotic trajectories, human demonstration movies, and artificial information. The purpose is broad generalization throughout duties and robotic platforms.
NVIDIA has proven GR00T N1 working on actual humanoid {hardware}, together with bimanual manipulation. Like giant language fashions (LLMs), it emphasizes pretraining as soon as and adapting broadly.
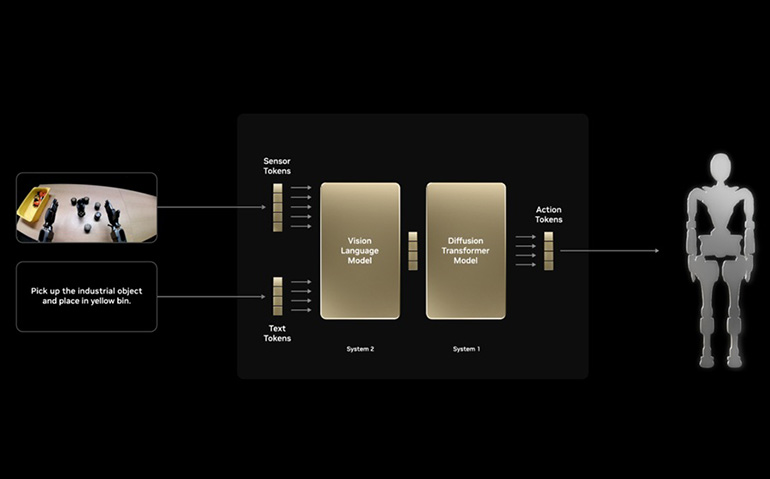
GR001 N1 mannequin structure. Supply: NVIDIA
RT-2 – Scalable embodied AI
RT-2, from Google DeepMind, extends the Gemini 2.0 multimodal spine into steady motion management. It demonstrates robust generalization to unseen objects and multi-step duties. Latest on-device variants cut back latency and help offline operation.
Collectively, these approaches set the stage for a way VLAs combine with bodily robotic stacks.
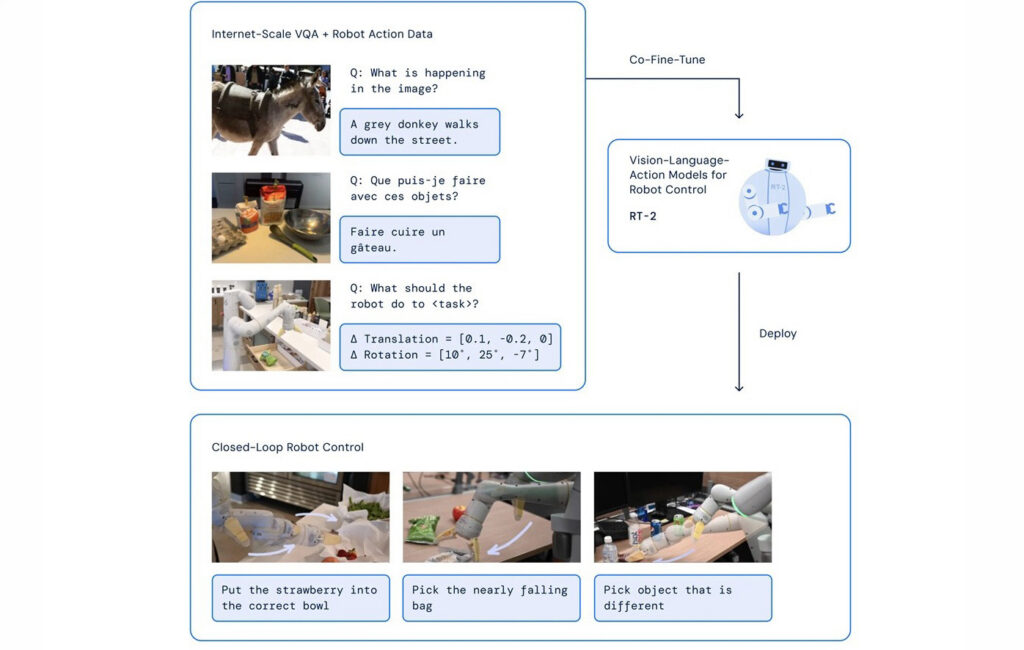
RT-2 structure. Supply: Google DeepMind
How VLAs combine with bodily robotic stacks
Imaginative and prescient-language-action fashions depend on wealthy, fused sensing. RGB and depth cameras, lidar, IMUs, and power/torque sensors feed multimodal encoders so the mannequin sees geometry, texture, and speak to states in actual time.
Onboard compute shapes what’s potential. Actual-time inference for multimodal transformers calls for GPUs or specialised accelerators. In any other case, latency kills security and responsiveness.
That creates a trade-off: Run the VLA domestically for low latency and offline operation, or use a hybrid cloud setup for heavier reasoning and mannequin updates. RT-2’s on-device variant illustrates the native method, reduces community delays, and permits quicker reactions.
Subsequent, we’ll study sensible deployment challenges and issues that business groups should face when adopting VLAs.
Sensible deployment challenges and issues
Whereas VLAs promise transformative talents, actual deployment nonetheless faces onerous challenges.
Actual-world robustness
Actual-world robustness stays a serious hurdle. VLAs may be brittle when lighting adjustments, scenes are cluttered, or sensors report noisy information. Making certain dependable habits in various settings calls for in depth testing and security assurance.
{Hardware} limits—warmth, energy draw, and communication bandwidth—can additional constrain efficiency on cell robots.
Effectivity and mannequin dimension
Effectivity and mannequin dimension additionally matter. Giant VLA fashions pressure onboard assets. Rising work on smaller, environment friendly variants (e.g., analysis into compact VLA fashions) reveals that leaner architectures can nonetheless ship significant management for particular duties.
Benchmarking and requirements
Benchmarking and requirements are nascent. Conferences like ICLR see a surge of VLA analysis, however the discipline lacks broadly accepted benchmarks and check suites for honest analysis throughout each simulation and actual robots.
The place VLA analysis and trade are headed
Trying forward, vision-language-action analysis reveals clear momentum. The subsequent wave focuses on deeper multimodal and embodied AI programs that transfer past at the moment’s designs.
One main shift seems in structure. Researchers now discover diffusion-based and hybrid fashions as a substitute of purely autoregressive insurance policies. These approaches generate motion sequences extra effectively and align reasoning with management, which improves generalization throughout duties.
One other development facilities on embodied cognition. New fashions join steady notion with time-aware motion planning and intermediate reasoning. This helps robots perceive context over longer horizons and full multi-step duties extra reliably.
The ecosystem additionally expands shortly. Open frameworks and shared datasets, equivalent to community-driven efforts like LeRobot, make experimentation simpler and encourage collaboration throughout labs and corporations. Collectively, these traits level towards VLAs that scale higher, adapt quicker, and see wider adoption in business robotics.
A sensible step towards really autonomous robots
Imaginative and prescient-language-action fashions mark a transparent break from older, modular robotics pipelines. They join notion, language understanding, and management in a single system, which permits robots to interpret directions and act with way more flexibility.
For business robotics groups, this shift opens the door to natural-language interfaces, stronger generalization throughout duties, and robots that function extra naturally in human areas.
I see VLAs as a sensible step towards machines that really perceive what to do and do it. Success, nevertheless, will depend on considerate adoption that balances bold capabilities with {hardware} limits, security necessities, and real-world deployment constraints.
 Concerning the creator
Concerning the creator
 Concerning the creator
Concerning the creatorPratik Shinde is a content material and web optimization Knowledgeable at Omdena and a full-stack digital marketer with over six years of expertise driving natural progress for SaaS, AI, and know-how manufacturers. He takes a holistic method to advertising and marketing by combining web optimization, content material technique, paid acquisition, and AI-powered automation to ship measurable enterprise outcomes.
Beforehand, Shinde has led high-impact web optimization and link-building initiatives for a number of world SaaS corporations, serving to them develop authority, visitors, and conversions throughout aggressive markets.