



Google has launched Gemini 3.1 Flash Dwell in preview for builders by the Gemini Dwell API in Google AI Studio. This mannequin targets low-latency, extra pure, and extra dependable real-time voice interactions, serving as Google’s ‘highest-quality audio and speech model to date.’ By natively processing multimodal streams, the discharge offers a technical basis for constructing voice-first brokers that transfer past the latency constraints of conventional turn-based LLM architectures.
Is it the top of ‘Wait-Time Stack‘?
The core downside with earlier voice-AI implementations was the ‘wait-time stack’: Voice Exercise Detection (VAD) would look ahead to silence, then Transcribe (STT), then Generate (LLM), then Synthesize (TTS). By the point the AI spoke, the human had already moved on.
Gemini 3.1 Flash Dwell collapses this stack by native audio processing. The mannequin doesn’t simply ‘read’ a transcript; it processes acoustic nuances immediately. In response to Google’s inside metrics, the mannequin is considerably more practical at recognizing pitch and tempo than the earlier 2.5 Flash Native Audio.
Much more spectacular is its efficiency in ‘noisy’ real-world environments. In exams involving visitors noise or background chatter, the three.1 Flash Dwell mannequin discerned related speech from environmental sounds with unprecedented accuracy. This can be a vital win for builders constructing cell assistants or customer support brokers that function within the wild reasonably than a quiet studio.
The Multimodal Dwell API
For AI devs, the actual shift occurs inside the Multimodal Dwell API. This can be a stateful, bi-directional streaming interface that makes use of WebSockets (WSS) to take care of a persistent connection between the shopper and the mannequin.
In contrast to normal RESTful APIs that deal with one request at a time, the Dwell API permits for a steady stream of information. Right here is the technical breakdown of the info pipeline:
- Audio Enter: The mannequin expects uncooked 16-bit PCM audio at 16kHz, little-endian.
- Audio Output: It returns uncooked PCM audio knowledge, successfully bypassing the latency of a separate text-to-speech step.
- Visible Context: You possibly can stream video frames as particular person JPEG or PNG pictures at a charge of roughly 1 body per second (FPS).
- Protocol: A single server occasion can now bundle a number of content material components concurrently—equivalent to audio chunks and their corresponding transcripts. This simplifies client-side synchronization considerably.
The mannequin additionally helps Barge-in, permitting customers to interrupt the AI mid-sentence. As a result of the connection is bi-directional, the API can instantly halt its audio technology buffer and course of new incoming audio, mimicking the cadence of human dialogue.
Benchmarking Agentic Reasoning
Google’s AI analysis group isn’t simply optimizing for velocity; they’re optimizing for utility. The discharge highlights the mannequin’s efficiency on ComplexFuncBench Audio. This benchmark measures an AI’s skill to carry out multi-step perform calling with numerous constraints based mostly purely on audio enter.
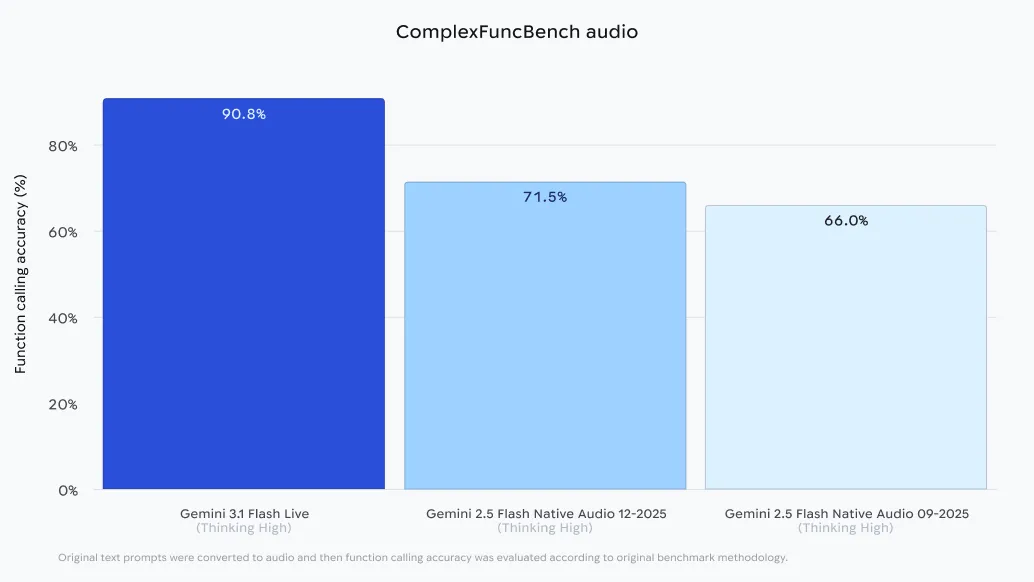
Gemini 3.1 Flash Dwell scored a staggering 90.8% on this benchmark. For builders, this implies a voice agent can now purpose by advanced logic—like discovering particular invoices and emailing them based mostly on a value threshold—while not having a textual content middleman to suppose first.
| Benchmark | Rating | Focus Space |
| ComplexFuncBench Audio | 90.8% | Multi-step perform calling from audio enter. |
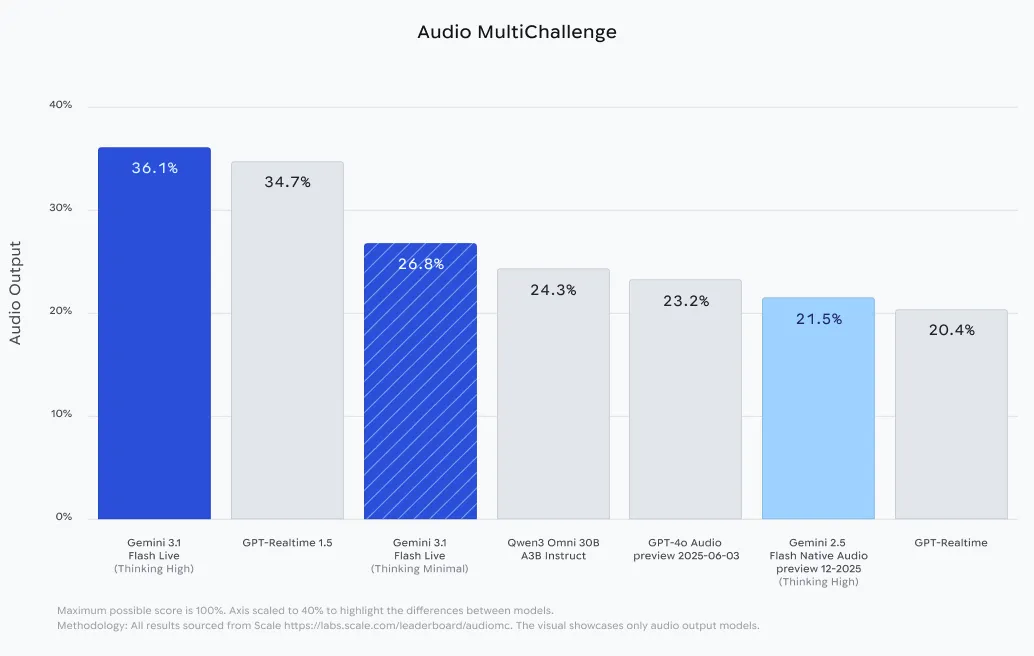
| Audio MultiChallenge | 36.1% | Instruction following in noisy/interrupted speech (with considering). |
| Context Window | 128k | Complete tokens out there for session reminiscence and gear definitions. |
The mannequin’s efficiency on the Audio MultiChallenge (36.1% with considering enabled) additional proves its resilience. This benchmark exams the AI’s skill to take care of focus and comply with advanced directions regardless of the interruptions, stutters, and background noise typical of real-world human speech.

Developer Controls: thinkingLevel
A standout characteristic for AI devs is the flexibility to tune the mannequin’s reasoning depth. Utilizing the thinkingLevel parameter, builders can select between minimal, low, medium, and excessive.
- Minimal: That is the default for Dwell periods, prioritized for the bottom doable Time to First Token (TTFT).
- Excessive: Whereas it will increase latency, it permits the mannequin to carry out deeper “thinking” steps earlier than responding, which is critical for advanced problem-solving or debugging duties delivered through stay video.
Closing the Information Hole: Gemini Expertise
As AI APIs evolve quickly, conserving documentation up-to-date inside a developer’s personal coding instruments is a problem. To deal with this, Google’s AI group maintains the google-gemini/gemini-skills repository. This can be a library of ‘skills’—curated context and documentation—that may be injected into an AI coding assistant’s immediate to enhance its efficiency.
The repository features a particular gemini-live-api-dev ability targeted on the nuances of WebSocket periods and audio/video blob dealing with. The broader Gemini Expertise repository experiences that including a related ability improved code-generation accuracy to 87% with Gemini 3 Flash and 96% with Gemini 3 Professional. Through the use of these abilities, builders can guarantee their coding brokers are using essentially the most present greatest practices for the Dwell API.
Key Takeaways
- Native Multimodal Structure: It collapses the standard ‘transcribe-reason-synthesize’ stack right into a single native audio-to-audio course of, considerably decreasing latency and enabling extra pure pitch and tempo recognition.
- Stateful Bidirectional Streaming: The mannequin makes use of WebSockets (WSS) for full-duplex communication, permitting for ‘Barge-in’ (person interruptions) and simultaneous transmission of audio, video frames, and transcripts.
- Excessive-Accuracy Agentic Reasoning: It’s optimized for triggering exterior instruments immediately from voice, reaching a 90.8% rating on the ComplexFuncBench Audio for multi-step perform calling.
- Tunable ‘Thinking’ Controls: Builders can steadiness conversational velocity in opposition to reasoning depth utilizing the brand new
thinkingLevelparameter (starting from minimal to excessive) inside a 128k token context window. - Preview Standing & Constraints: Presently out there in developer preview, the mannequin requires 16-bit PCM audio (16kHz enter/24kHz output) and presently helps solely synchronous perform calling and particular content-part bundling.
Take a look at the Technical particulars, Repo and Docs. Additionally, be at liberty to comply with us on Twitter and don’t neglect to hitch our 120k+ ML SubReddit and Subscribe to our Publication. Wait! are you on telegram? now you may be part of us on telegram as effectively.