



Two years in the past, Cloudflare deployed our twelfth Era server fleet, based mostly on AMD EPYC™ Genoa-X processors with their huge 3D V-Cache. That cache-heavy structure was an ideal match for our request dealing with layer, FL1 on the time. However as we evaluated next-generation {hardware}, we confronted a dilemma — the CPUs providing the most important throughput beneficial properties got here with a major cache discount. Our legacy software program stack wasn’t optimized for this, and the potential throughput advantages had been being capped by growing latency.
This weblog describes how the FL2 transition, our Rust-based rewrite of Cloudflare’s core request dealing with layer, allowed us to show Gen 13’s full potential and unlock efficiency beneficial properties that may have been unimaginable on our earlier stack. FL2 removes the dependency on the bigger cache, permitting for efficiency to scale with cores whereas sustaining our SLAs. At the moment, we’re proud to announce the launch of Cloudflare’s Gen 13 based mostly on AMD EPYC™ fifth Gen Turin-based servers operating FL2, successfully capturing and scaling efficiency on the edge.
What AMD EPYCTurin brings to the desk
AMD’s EPYC™ fifth Era Turin-based processors ship greater than only a core rely enhance. The structure delivers enhancements throughout a number of dimensions of what Cloudflare servers require.
2x core rely: as much as 192 cores versus Gen 12’s 96 cores, with SMT offering 384 threads
Improved IPC: Zen 5’s architectural enhancements ship higher instructions-per-cycle in comparison with Zen 4
Higher energy effectivity: Regardless of the upper core rely, Turin consumes as much as 32% fewer watts per core in comparison with Genoa-X
DDR5-6400 help: Greater reminiscence bandwidth to feed all these cores
Nonetheless, Turin’s excessive density OPNs make a deliberate tradeoff: prioritizing throughput over per core cache. Our evaluation throughout the Turin stack highlighted this shift. For instance, evaluating the very best density Turin OPN to our Gen 12 Genoa-X processors reveals that Turin’s 192 cores share 384MB of L3 cache. This leaves every core with entry to only 2MB, one-sixth of Gen 12’s allocation. For any workload that depends closely on cache locality, which ours did, this discount posed a critical problem.
Era | Processor | Cores/Threads | L3 Cache/Core |
Gen 12 | AMD Genoa-X 9684X | 96C/192T | 12MB (3D V-Cache) |
Gen 13 Choice 1 | AMD Turin 9755 | 128C/256T | 4MB |
Gen 13 Choice 2 | AMD Turin 9845 | 160C/320T | 2MB |
Gen 13 Choice 3 | AMD Turin 9965 | 192C/384T | 2MB |
Diagnosing the issue with efficiency counters
For our FL1 request dealing with layer, NGINX- and LuaJIT-based code, this cache discount offered a major problem. However we did not simply assume it will be an issue; we measured it.
In the course of the CPU analysis section for Gen 13, we collected CPU efficiency counters and profiling knowledge to determine precisely what was occurring beneath the hood utilizing AMD uProf device. The info confirmed:
L3 cache miss charges elevated dramatically in comparison with Gen 12’s server outfitted with 3D V-cache processors
Reminiscence fetch latency dominated request processing time as knowledge that beforehand stayed in L3 now required journeys to DRAM
The latency penalty scaled with utilization as we pushed CPU utilization larger, and cache rivalry worsened
L3 cache hits full in roughly 50 cycles; L3 cache misses requiring DRAM entry take 350+ cycles, an order of magnitude distinction. With 6x much less cache per core, FL1 on Gen 13 was hitting reminiscence way more usually, incurring latency penalties.
The tradeoff: latency vs. throughput
Our preliminary assessments operating FL1 on Gen 13 confirmed what the efficiency counters had already instructed. Whereas the Turin processor might obtain larger throughput, it got here at a steep latency price.
Metric | Gen 12 (FL1) | Gen 13 – AMD Turin 9755 (FL1) | Gen 13 – AMD Turin 9845 (FL1) | Gen 13 – AMD Turin 9965 (FL1) | Delta |
Core rely | baseline | +33% | +67% | +100% | |
FL throughput | baseline | +10% | +31% | +62% | Enchancment |
Latency at low to average CPU utilization | baseline | +10% | +30% | +30% | Regression |
Latency at excessive CPU utilization | baseline | > 20% | > 50% | > 50% | Unacceptable |
The Gen 13 analysis server with AMD Turin 9965 that generated 60% throughput acquire was compelling, and the efficiency uplift supplied essentially the most enchancment to Cloudflare’s complete price of possession (TCO).
However a greater than 50% latency penalty will not be acceptable. The rise in request processing latency would straight influence buyer expertise. We confronted a well-recognized infrastructure query: will we settle for an answer with no TCO profit, settle for the elevated latency tradeoff, or discover a solution to increase effectivity with out including latency?
Incremental beneficial properties with efficiency tuning
To discover a path to an optimum final result, we collaborated with AMD to investigate the Turin 9965 knowledge and run focused optimization experiments. We systematically examined a number of configurations:
{Hardware} Tuning: Adjusting {hardware} prefetchers and Information Material (DF) Probe Filters, which confirmed solely marginal beneficial properties
Scaling Employees: Launching extra FL1 staff, which improved throughput however cannibalized sources from different manufacturing providers
CPU Pinning & Isolation: Adjusting workload isolation configurations to search out optimum combine, with restricted success
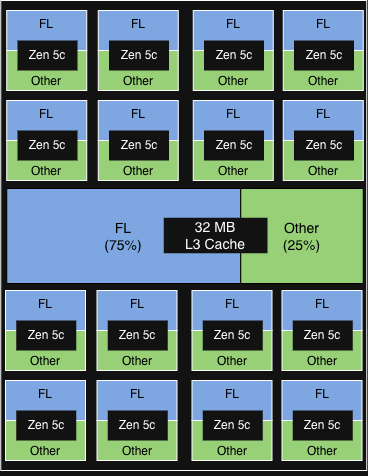
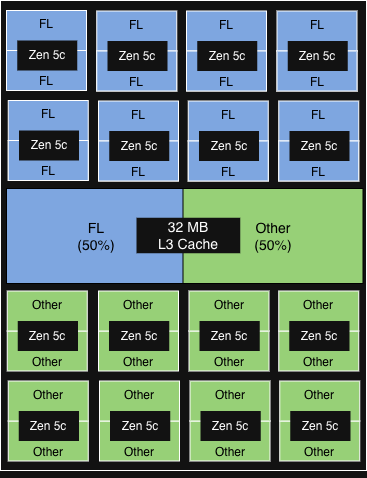
The configuration that in the end supplied essentially the most worth was AMD’s Platform High quality of Service (PQOS). PQOS extensions allow fine-grained regulation of shared sources like cache and reminiscence bandwidth. Since Turin processors consist of 1 I/O Die and as much as 12 Core Complicated Dies (CCDs), every sharing an L3 cache throughout as much as 16 cores, we put this to the take a look at. Right here is how the completely different experimental configurations carried out.
First, we used PQOS to allocate a devoted L3 cache share inside a single CCD for FL1, the beneficial properties had been minimal. Nonetheless, after we scaled the idea to the socket degree, dedicating an total CCD strictly to FL1, we noticed significant throughput beneficial properties whereas preserving latency acceptable.
The chance: FL2 was already in progress
{Hardware} tuning and useful resource configuration supplied modest beneficial properties, however to really unlock the efficiency potential of the Gen 13 structure, we knew we must rewrite our software program stack to essentially change the way it utilized system sources.
Thankfully, we weren’t ranging from scratch. As we introduced throughout Birthday Week 2025, we had already been rebuilding FL1 from the bottom up. FL2 is an entire rewrite of our request dealing with layer in Rust, constructed on our Pingora and Oxy frameworks, changing 15 years of NGINX and LuaJIT code.
The FL2 venture wasn’t initiated to unravel the Gen 13 cache downside — it was pushed by the necessity for higher safety (Rust’s reminiscence security), sooner improvement velocity (strict module system), and improved efficiency throughout the board (much less CPU, much less reminiscence, modular execution).
FL2’s cleaner structure, with higher reminiscence entry patterns and fewer dynamic allocation, won’t depend upon huge L3 caches the way in which FL1 did. This gave us a chance to make use of the FL2 transition to show whether or not Gen 13’s throughput beneficial properties may very well be realized with out the latency penalty.
Proving it out: FL2 on Gen 13
Because the FL2 rollout progressed, manufacturing metrics from our Gen 13 servers validated what we had hypothesized.
Metric | Gen 13 AMD Turin 9965 (FL1) | Gen 13 AMD Turin 9965 (FL2) |
FL requests per CPU% | baseline | 50% larger |
Latency vs Gen 12 | baseline | 70% decrease |
Throughput vs Gen 12 | 62% larger | 100% larger |
The out-of-the-box effectivity beneficial properties on our new FL2 stack had been substantial, even earlier than any system optimizations. FL2 slashed the latency penalty by 70%, permitting us to push Gen 13 to larger CPU utilization whereas strictly assembly our latency SLAs. Below FL1, this could have been unimaginable.
By successfully eliminating the cache bottleneck, FL2 permits our throughput to scale linearly with core rely. The influence is plain on the high-density AMD Turin 9965: we achieved a 2x efficiency acquire, unlocking the true potential of the {hardware}. With additional system tuning, we anticipate to squeeze much more energy out of our Gen 13 fleet.
Generational enchancment with Gen 13
With FL2 unlocking the immense throughput of the high-core-count AMD Turin 9965, we’ve got formally chosen these processors for our Gen 13 deployment. {Hardware} qualification is full, and Gen 13 servers at the moment are delivery at scale to help our international rollout.
Gen 12 | Gen 13 | |
Processor | AMD EPYC™ 4th Gen Genoa-X 9684X | AMD EPYC™ fifth Gen Turin 9965 |
Core rely | 96C/192T | 192C/384T |
FL throughput | baseline | As much as +100% |
Efficiency per watt | baseline | As much as +50% |
As much as 2x throughput vs Gen 12 for uncompromising buyer expertise: By doubling our throughput capability whereas staying inside our latency SLAs, we assure our functions stay quick and responsive, and capable of soak up huge site visitors spikes.
50% higher efficiency/watt vs Gen 12 for sustainable scaling: This acquire in energy effectivity not solely reduces knowledge heart enlargement prices, however permits us to course of rising site visitors with a vastly decrease carbon footprint per request.
60% larger rack throughput vs Gen 12 for international edge upgrades: As a result of we achieved this throughput density whereas preserving the rack energy funds fixed, we will seamlessly deploy this subsequent technology compute anyplace on the earth throughout our international edge community, delivering high tier efficiency precisely the place our clients need it.
Gen 13 + FL2: prepared for the sting
Our legacy request serving layer FL1 hit a cache rivalry wall on Gen 13, forcing an unacceptable tradeoff between throughput and latency. As an alternative of compromising, we constructed FL2.
Designed with a vastly leaner reminiscence entry sample, FL2 removes our dependency on huge L3 caches and permits linear scaling with core rely. Working on the Gen 13 AMD Turin platform, FL2 unlocks 2x the throughput and a 50% increase in energy effectivity all whereas preserving latency inside our SLAs. This leap ahead is a superb reminder of the significance of hardware-software co-design. Unconstrained by cache limits, Gen 13 servers at the moment are able to be deployed to serve hundreds of thousands of requests throughout Cloudflare’s international community.
In case you’re enthusiastic about engaged on infrastructure at international scale, we’re hiring.