



Conversational AI has long faced a tough tradeoff: be fast or be smart. Real-time speech-to-speech (S2S) models — the ones behind natural-sounding voice assistants — start responding almost immediately, but their answers tend to lack depth. On the other hand, cascaded systems that pass speech through a large language model (LLM) deliver much richer responses, but the processing delay is long enough to make conversations feel awkward and mechanical. Sakana AI, a research lab based in Tokyo, has unveiled KAME (Knowledge-Access Model Extension), a hybrid design that preserves the near-instant response time of a direct S2S system while pulling in the deeper knowledge of a back-end LLM on the fly.
The Problem: Two Approaches, Two Compromises
To appreciate what KAME brings to the table, it’s worth looking at the two established approaches it aims to bridge.
A direct S2S model like Moshi (built by KyutAI) is a single transformer that takes audio tokens as input and produces audio tokens as output in a continuous loop. Since it doesn’t rely on any external components, its response time is remarkably fast — for many questions, the model begins replying before the user has even finished speaking. However, because audio signals carry far more information than text, the model must dedicate a large share of its capacity to capturing paralinguistic cues such as tone, emotion, and rhythm. That leaves less room for storing factual knowledge and performing complex reasoning.
A cascaded system works differently: it sends the user’s speech through an Automatic Speech Recognition (ASR) model, passes the transcribed text to a powerful LLM, and then converts the LLM’s written reply back into speech using a Text-to-Speech (TTS) engine. The quality of knowledge is excellent — you can connect any state-of-the-art LLM — but the system has to wait for the user to finish speaking before ASR and LLM processing can even start. This leads to a median delay of roughly 2.1 seconds, which is enough to noticeably disrupt the natural rhythm of conversation.
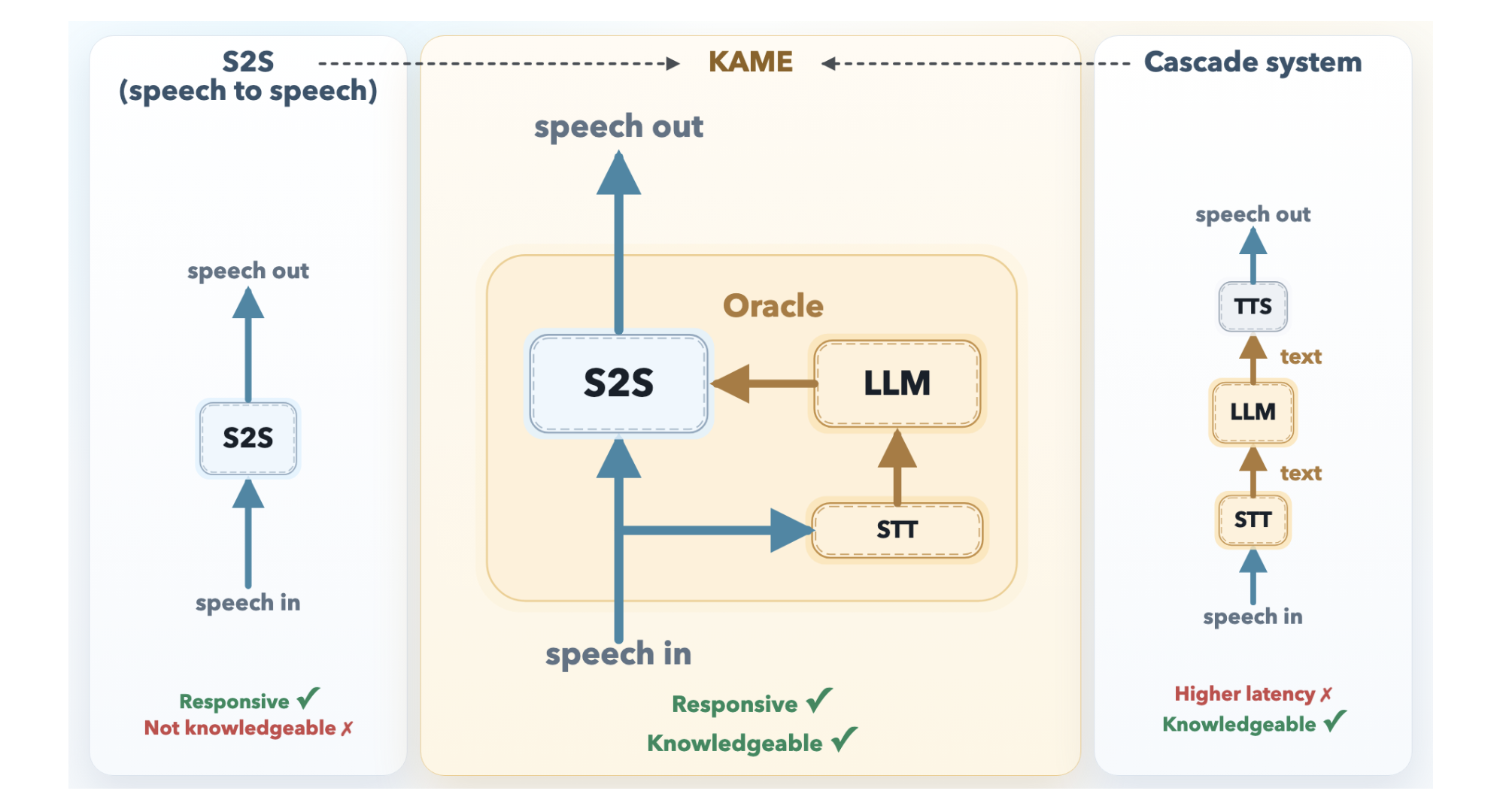
KAME’s Architecture: Talking While Processing
KAME works as a tandem setup with two components running independently and at the same time.
The front-end S2S module is built on the Moshi architecture and handles audio in real time, processing discrete audio tokens at intervals of roughly 80 milliseconds. It starts producing a spoken reply right away. Inside, Moshi’s original three-stream layout — input audio, inner monologue (text), and output audio — is expanded in KAME with a fourth stream: the oracle stream. This is the core innovation.
The back-end LLM module pairs a streaming speech-to-text (STT) component with a full-scale LLM. As the user talks, the STT component continuously assembles a partial transcript and sends it periodically to the back-end LLM. For each partial transcript it gets, the LLM produces a candidate text response — referred to as an oracle — and streams it back to the front-end. Since the user is still speaking, these oracles begin as informed guesses and grow more accurate as the transcript becomes more complete.
The front-end S2S transformer then shapes its ongoing speech output using both its own internal context and these incoming oracle tokens. When a newer, more accurate oracle arrives, the model can adjust its course — effectively revising its response mid-sentence, much like a person would. Because both modules operate asynchronously and independently, the initial response delay stays close to zero.
Training on Simulated Oracles
A major hurdle is the absence of naturally available datasets containing oracle signals. To overcome this, Sakana AI introduced a method named Simulated Oracle Augmentation. Leveraging a “simulator” large language model (LLM) and a standard dataset of conversations (pairs of user inputs and correct responses), the team crafted synthetic oracle sequences that replicate outputs a real-time LLM would generate at varying stages of transcript completion. They established six distinct hint levels (0–5), spanning from a completely uninformed guess at level 0 to the exact ground-truth answer at level 5. KAME’s training dataset comprised 56,582 artificial dialogues sourced from MMLU-Pro, GSM8K, and HSSBench, transformed into speech via text-to-speech (TTS) technology and enriched with these incremental oracle cues.
Results: Near-Cascaded Quality, Near-Zero Latency
Benchmarks conducted on a speech-synthesized subset of the MT-Bench multi-turn Q&A evaluation—focusing specifically on reasoning, STEM, and humanities domains (excluding Coding, Extraction, Math, Roleplay, and Writing, deemed less suitable for voice-based interaction)—demonstrate a striking performance leap. While Moshi achieves an average score of 2.05, KAME powered by gpt-4.1 reaches 6.43, and with claude-opus-4-1, it attains 6.23—all with minimal, near-zero latency comparable to Moshi. In contrast, the top-performing cascaded system, Unmute (also leveraging gpt-4.1), scores 7.70 but exhibits a median response delay of 2.1 seconds, significantly slower than KAME.
To disentangle backend LLM capability from timing artifacts, the researchers also assessed the final text responses from the last oracle injection in each KAME session directly—effectively sidestepping the issue of premature response generation. These scores averaged 7.79 (reasoning: 6.48, STEM: 8.34, humanities: 8.56), closely matching Unmute’s 7.70. This validates that KAME’s performance gap relative to cascaded systems does not reflect a limitation in the backend LLM’s knowledge base, but rather stems from initiating speech output before the full user query is fully processed.
Importantly, KAME is entirely backend-agnostic. Although the frontend was trained primarily using gpt-4.1-nano, switching to alternative frontier models like claude-opus-4-1 or gemini-2.5-flash during inference demands no retraining. In Sakana AI’s trials, claude-opus-4-1 showed stronger results on reasoning challenges, whereas gpt-4.1 excelled in humanities—indicating that users can dynamically assign queries to the most suitable LLM based on task requirements, without modifying the frontend.
Key Takeaways
- KAME resolves the speed-versus-knowledge dilemma in conversational AI by operating a frontend speech-to-speech model and a backend LLM concurrently and independently—the S2S model replies instantly while the LLM feeds progressively refined “oracle” insights in real time, transforming the model from “think, then speak” to a “speak while thinking” paradigm.
- Significant performance improvements come with no added delay—KAME boosts the MT-Bench score from 2.05 (Moshi baseline) to 6.43, nearing Unmute’s 7.70, all while preserving near-zero median response latency, unlike Unmute’s 2.1-second lag.
- The system is fully backend-agnostic—the frontend was trained with gpt-4.1-nano, but any state-of-the-art LLM (gpt-4.1, claude-opus-4-1, gemini-2.5-flash) can be swapped in seamlessly at inference time, enabling flexible, domain-optimized LLM routing without retraining.
Explore the Model Weights, Research Paper, Inference Code, and Technical Documentation. Also, stay updated by following us on Twitter, joining our 130k+ ML SubReddit, and subscribing to our Newsletter. Are you on Telegram? You can now connect with us there too.
Interested in collaborating to promote your GitHub Repository, Hugging Face Page, Product Launch, or Webinar? Get in touch with us