



Picture by Editor
# Introduction
Exploratory information evaluation (EDA) is a vital stage previous to deeper information evaluation processes or constructing data-driven AI techniques, similar to these primarily based on machine studying fashions. Whereas fixing widespread, real-world information high quality points and inconsistencies is usually deferred to subsequent levels of the information pipeline, EDA can also be a superb alternative to proactively detect these points early on — earlier than silently biasing outcomes, degrading mannequin efficiency, or compromising downstream decision-making.
Under, we curate an inventory that comprises 7 Python tips relevant to your early EDA processes, particularly by successfully figuring out and fixing a wide range of information high quality points.
As an instance these tips, we’ll use a synthetically generated workers dataset, through which we’ll deliberately inject a wide range of information high quality points to exemplify detect and deal with them. Earlier than attempting the tips out, be sure you first copy and paste the next preamble code in your coding setting:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# PREAMBLE CODE THAT RANDOMLY CREATES A DATASET AND INTRODUCES QUALITY ISSUES IN IT
np.random.seed(42)
n = 1000
df = pd.DataFrame({
"age": np.random.regular(40, 12, n).spherical(),
"income": np.random.regular(60000, 15000, n),
"experience_years": np.random.regular(10, 5, n),
"department": np.random.alternative(
["Sales", "Engineering", "HR", "sales", "Eng", "HR "], n
),
"performance_score": np.random.regular(3, 0.7, n)
})
# Randomly injecting information points to the dataset
# 1. Lacking values
df.loc[np.random.choice(n, 80, replace=False), "income"] = np.nan
df.loc[np.random.choice(n, 50, replace=False), "department"] = np.nan
# 2. Outliers
df.loc[np.random.choice(n, 10), "income"] *= 5
df.loc[np.random.choice(n, 10), "age"] = -5
# 3. Invalid values
df.loc[np.random.choice(n, 15), "performance_score"] = 7
# 4. Skewness
df["bonus"] = np.random.exponential(2000, n)
# 5. Extremely correlated options
df["income_copy"] = df["income"] * 1.02
# 6. Duplicated entries
df = pd.concat([df, df.iloc[:20]], ignore_index=True)
df.head()
# 1. Detecting Lacking Values through Heatmaps
Whereas there are capabilities in Python libraries like Pandas that rely the variety of lacking values for every attribute in your dataset, a pretty method to have a fast glimpse of all lacking values in your dataset — and which columns or attributes comprise some — is by visualizing a heatmap aided by the isnull() perform, thus plotting white, barcode-like strains for each single lacking worth throughout your complete dataset, horizontally organized by attributes.
plt.determine(figsize=(10, 5))
sns.heatmap(df.isnull(), cbar=False)
plt.title("Missing Value Heatmap")
plt.present()
df.isnull().sum().sort_values(ascending=False)
Heatmap to detect lacking values | Picture by Writer
# 2. Eradicating Duplicates
This trick is a traditional: easy, but very efficient to rely the variety of duplicated situations (rows) in your dataset, after which you’ll apply drop_duplicates() to take away them. By default, this perform preserves the primary incidence of every duplicated row and eliminates the remainder. Nonetheless, this conduct could be modified, as an example, through the use of the maintain="last" choice to retain the final incidence as an alternative of the primary one, or maintain=False to eliminate all duplicated rows solely. The conduct to decide on will rely in your particular downside wants.
duplicate_count = df.duplicated().sum()
print(f"Number of duplicate rows: {duplicate_count}")
# Take away duplicates
df = df.drop_duplicates()
# 3. Figuring out Outliers Utilizing the Inter-Quartile Vary Methodology
The inter-quartile vary (IQR) technique is a statistics-backed method to establish information factors which may be deemed as outliers or excessive values, as a result of being considerably distant from the remainder of the factors. This trick supplies an implementation of the IQR technique that may be replicated for various numeric attributes, similar to “income”:
def detect_outliers_iqr(information, column):
Q1 = information[column].quantile(0.25)
Q3 = information[column].quantile(0.75)
IQR = Q3 - Q1
decrease = Q1 - 1.5 * IQR
higher = Q3 + 1.5 * IQR
return information[(data[column] < decrease) | (information[column] > higher)]
outliers_income = detect_outliers_iqr(df, "income")
print(f"Income outliers: {len(outliers_income)}")
# Non-obligatory: cap them
Q1 = df["income"].quantile(0.25)
Q3 = df["income"].quantile(0.75)
IQR = Q3 - Q1
decrease = Q1 - 1.5 * IQR
higher = Q3 + 1.5 * IQR
df["income"] = df["income"].clip(decrease, higher)
# 4. Managing Inconsistent Classes
In contrast to outliers, that are usually related to numeric options, inconsistent classes in categorical variables can stem from numerous elements, e.g. handbook inconsistencies like uppercase or lowercase initials in names or domain-specific variations. Due to this fact, the best method to deal with them would possibly partly contain subject material experience to determine on the best set of classes deemed as legitimate. This instance applies administration of class inconsistencies in division names that consult with the identical division.
print("Before cleaning:")
print(df["department"].value_counts(dropna=False))
df["department"] = (
df["department"]
.str.strip()
.str.decrease()
.substitute({
"eng": "engineering",
"sales": "sales",
"hr": "hr"
})
)
print("nAfter cleaning:")
print(df["department"].value_counts(dropna=False))
# 5. Checking and Validating Ranges
Whereas outliers are statistically distant values, invalid values rely on domain-specific constraints, e.g. values for an “age” attribute can’t be adverse. This instance identifies adverse values for the “age” attribute and replaces them with NaN — discover that these invalid values are was lacking values, therefore a downstream technique for dealing with them may be wanted.
invalid_age = df[df["age"] < 0]
print(f"Invalid ages: {len(invalid_age)}")
# Repair by setting to NaN
df.loc[df["age"] < 0, "age"] = np.nan
# 6. Making use of Log-Remodel for Skewed Knowledge
Skewed information attributes like “bonus” in our instance dataset are normally higher reworked into one thing that resembles a traditional distribution, as this facilitates the vast majority of downstream machine studying analyses. This trick applies a log transformation, displaying the earlier than and after of our information function.
skewness = df["bonus"].skew()
print(f"Bonus skewness: {skewness:.2f}")
plt.hist(df["bonus"], bins=40)
plt.title("Bonus Distribution (Original)")
plt.present()
# Log rework
df["bonus_log"] = np.log1p(df["bonus"])
plt.hist(df["bonus_log"], bins=40)
plt.title("Bonus Distribution (Log Transformed)")
plt.present()
Earlier than log-transform | Picture by Writer
After log-transform | Picture by Writer
# 7. Detecting Redundant Options through Correlation Matrix
We wrap up the listing simply the way in which we began: with a visible contact. Correlation matrices displayed as heatmaps assist rapidly establish pairs of options which are extremely correlated — a powerful signal that they could comprise redundant data that’s typically greatest minimized in subsequent evaluation. This instance additionally prints the top-5 most extremely correlated pairs of attributes for additional interpretability:
corr_matrix = df.corr(numeric_only=True)
plt.determine(figsize=(10, 6))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap="coolwarm")
plt.title("Correlation Matrix")
plt.present()
# Discover excessive correlations
high_corr = (
corr_matrix
.abs()
.unstack()
.sort_values(ascending=False)
)
high_corr = high_corr[high_corr < 1]
print(high_corr.head(5))
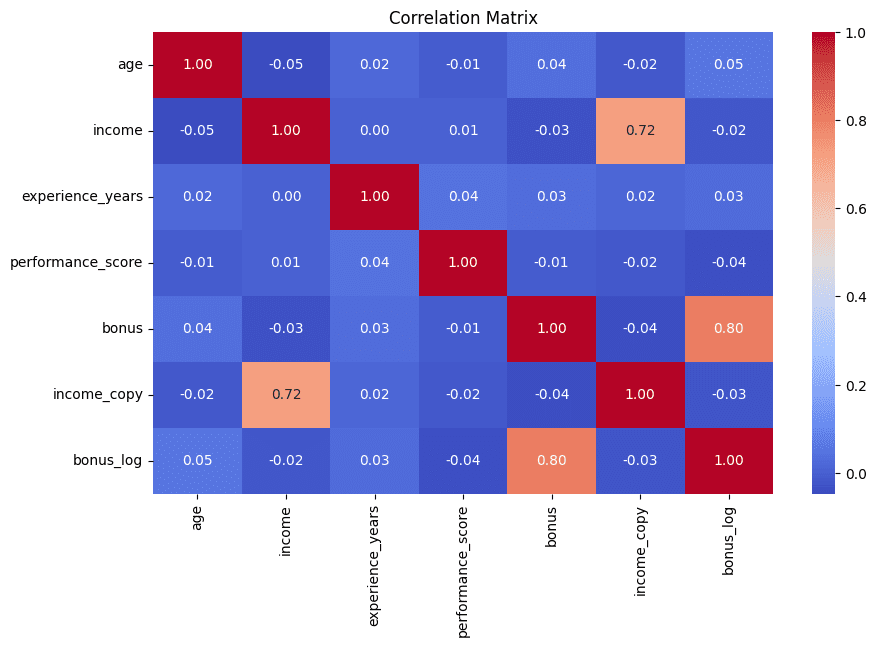
Correlation matrix to detect redundant options | Picture by Writer
# Wrapping Up
With the above listing, you will have discovered 7 helpful tips to benefit from your exploratory information evaluation, serving to reveal and take care of completely different varieties of knowledge high quality points and inconsistencies successfully and intuitively.
Iván Palomares Carrascosa is a frontrunner, author, speaker, and adviser in AI, machine studying, deep studying & LLMs. He trains and guides others in harnessing AI in the true world.