



The Volcano neighborhood is proud to announce the launch of Kthena, a brand new sub-project designed for international builders and MLOps engineers.
Kthena is a cloud native, high-performance system for Giant Language Mannequin (LLM) inference routing, orchestration, and scheduling, tailor-made particularly for Kubernetes. Engineered to handle the complexity of serving LLMs at manufacturing scale, Kthena delivers granular management and enhanced flexibility. By options like topology-aware scheduling, KV Cache-aware routing, and Prefill-Decode (PD) disaggregation, it considerably improves GPU/NPU utilization and throughput whereas minimizing latency.
As a sub-project of Volcano, Kthena extends Volcano’s capabilities past AI coaching, making a unified, end-to-end resolution for all the AI lifecycle.
The “Final Mile” Problem of LLM Serving
Whereas LLMs are reshaping industries, deploying them effectively on Kubernetes stays a posh methods engineering problem. Builders face 4 vital hurdles:
- Low Useful resource Utilization: The dynamic reminiscence footprint of LLM inference—particularly the KV Cache—creates huge strain on GPU/NPU assets. Conventional Spherical-Robin load balancers fail to understand these traits, resulting in a mixture of idle assets and queued requests that drives up prices.
- The Latency vs. Throughput Commerce-off: Inference consists of two distinct phases: Prefill (compute-intensive) and Decode (memory-bound). Coupled scheduling limits optimization. Whereas PD Disaggregation is the business commonplace resolution, environment friendly routing and scheduling for it stay tough.
- Complicated Multi-Mannequin Administration: Enterprises typically serve a number of fashions, variations, and LoRA adapters concurrently. Implementing honest scheduling, precedence administration, and dynamic routing is tough, main some to resort to inflexible 1:1 mappings between AI Gateways and fashions.
- Lack of Native K8s Integration: Many current options are both fragmented from the Kubernetes ecosystem or too complicated for traditional platform operations.
Kthena: The Clever Mind for Cloud Native Inference
Kthena was constructed to overcome these challenges. Somewhat than changing current inference engines (like vLLM or SGLang), Kthena acts as an clever orchestration layer on prime of them, deeply built-in into Kubernetes.
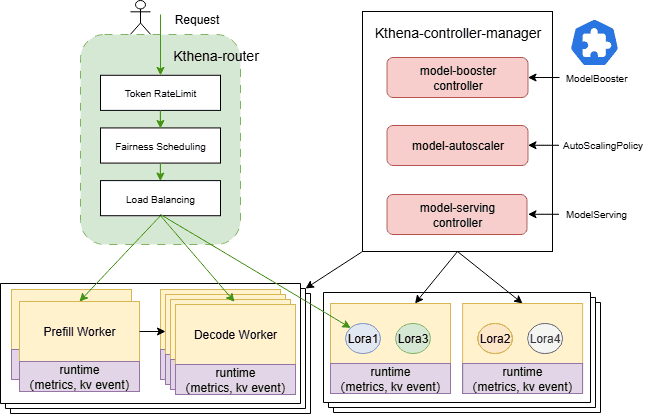
Kthena consists of two core parts:
- Kthena Router: A high-performance, multi-model router that acts because the entry level for all inference requests. It intelligently distributes site visitors to backend ModelServers based mostly on ModelRoute guidelines.
- Kthena Controller Supervisor: The management aircraft chargeable for workload orchestration and lifecycle administration. It reconciles Customized Useful resource Definitions (CRDs) like ModelBooster, ModelServing, and AutoScalingPolicy to transform declarative intent into runtime assets.
- It orchestrates ServingGroups and roles (Prefill/Decode).
- It handles topology-aware affinity, Gang scheduling, rolling updates, and failure restoration.
- It drives elastic scaling based mostly on outlined insurance policies.
Core Options and Benefits
1. Manufacturing-Grade Inference Orchestration (ModelServing)
Kthena introduces a Hierarchical Workload Structure (ModelServing -> ServingGroup -> Position).
- Unified API: A single API helps numerous patterns, from standalone deployments to complicated PD Disaggregation and Professional Parallelism (EP).
- Simplified Administration: For instance, a large PD deployment is managed as a single ModelServing useful resource containing a number of ServingGroups.
- Native PD Disaggregation: Kthena optimizes {hardware} utilization by routing compute-intensive Prefill duties to high-compute nodes and memory-bound Decode duties to Excessive Bandwidth Reminiscence (HBM) nodes. It helps unbiased scaling to dynamically regulate the Prefill/Decode ratio.
- Topology Consciousness & Gang Scheduling: Gang scheduling ensures that pods in a ServingGroup are scheduled as an atomic unit, stopping deadlocks. Topology consciousness minimizes knowledge transmission latency by inserting associated pods nearer collectively within the community cloth.
2. Out-of-the-Field Deployment (ModelBooster)
- Templates: Supplies built-in templates for mainstream fashions (together with PD separation), robotically producing obligatory routing and lifecycle assets.
- Flexibility: Covers basic eventualities whereas permitting granular management by way of ModelServing for complicated wants.
3. Clever, Mannequin-Conscious Routing
- Multi-Mannequin Routing: OpenAI API appropriate. Routes site visitors based mostly on headers or physique content material.
- Pluggable Algorithms: Consists of Least Request, Least Latency, KV Cache Consciousness, Prefix Cache Consciousness, LoRA Affinity, and Equity Scheduling.
- LoRA Sizzling-Swapping: Detects loaded LoRA adapters for non-disruptive hot-swapping and routing.
- Site visitors Governance: Helps canary releases, token-level price limiting, and failover.
- All-in-One Structure: Eliminates the necessity for a separate Envoy Gateway by natively dealing with routing logic.
4. Price-Pushed Autoscaling
- Homogeneous Scaling: Scales exactly based mostly on enterprise metrics (CPU/GPU/Reminiscence/Customized).
- Heterogeneous Optimization: Optimizes useful resource allocation throughout totally different accelerators based mostly on a “Price-Efficiency” ratio.
5. Broad {Hardware} & Engine Assist
- Inference Engines: Helps vLLM, SGLang, Triton/TGI, and extra by way of a unified API abstraction.
- Heterogeneous Compute: Permits co-location of GPU and NPU assets to stability value and Service Stage Targets (SLOs).
6. Constructed-in Circulation Management & Equity
- Equity Scheduling: Prioritizes site visitors based mostly on utilization historical past to stop “hunger” of low-priority customers.
- Circulation Management: Granular limits based mostly on consumer, mannequin, and token size.
Efficiency Benchmarks
In eventualities with lengthy system prompts (e.g., 4096 tokens), Kthena’s “KV Cache Consciousness + Least Request” technique delivers vital positive aspects in comparison with a random baseline:
- Throughput: Elevated by ~2.73x
- TTFT (Time To First Token): Diminished by ~73.5%
- Finish-to-Finish Latency: Diminished by >60%
| Plugin Configuration | Throughput (req/s) | TTFT (s) | E2E Latency (s) |
| Least Request + KVCacheAware | 32.22 | 9.22 | 0.57 |
| Least Request + Prefix Cache | 23.87 | 12.47 | 0.83 |
| Random | 11.81 | 25.23 | 2.15 |
Be aware: Whereas gaps slender with brief prompts, KV Cache consciousness affords decisive benefits for multi-turn conversations and template-heavy workloads.
Neighborhood & Business Assist
Kthena has already attracted widespread consideration and assist from business leaders since its inception.
“Open supply is the lifeblood of technical innovation and the first driver of business standardization. Because the initiator of Volcano, Huawei Cloud is proud to launch Kthena alongside our neighborhood companions.
This launch marks not solely a big milestone in Volcano’s technical evolution but in addition underscores Huawei Cloud’s enduring dedication to Cloud Native AI. By deeply integrating with infrastructure like Huawei Cloud CCE and CCI, Kthena unlocks the total potential of numerous computing energy—together with Ascend—delivering superior cost-efficiency to our clients.
By Kthena, we look ahead to collaborating with international builders to construct an open, thriving ecosystem that lays a strong basis for the clever transformation of industries worldwide.”
—— Xiaobo Qi, Director of Basic Computing Providers, Huawei Cloud
“Kthena additional solidifies Volcano’s management in clever workload scheduling. By leveraging Volcano’s unified scheduling and useful resource pooling capabilities, our platform addresses numerous compute necessities—spanning general-purpose computing, AI coaching, and inference—inside a single, unified framework.
This allows dynamic useful resource allocation throughout totally different eventualities, successfully eliminating useful resource silos. Trying forward, we’re excited to mix Kthena with Volcano’s elastic scaling and Volcano World’s cross-cluster scheduling to drive useful resource utilization to new heights.”
—— Lei Yang, PaaS R&D Director, China Telecom AI
“Since its inception, Volcano has developed in lockstep with the neighborhood to handle numerous AI eventualities, establishing a complete ecosystem for AI batch processing.
The launch of Kthena marks a serious milestone, extending Volcano’s capabilities into the vital realm of Giant Mannequin inference. It crystallizes years of Volcano’s greatest practices in scheduling, elasticity, and multi-architecture assist into a robust engine for unified orchestration and clever routing.
By leveraging the present Kubernetes and Volcano ecosystems, groups can obtain smarter scheduling choices and better compute effectivity at a decrease value. For DaoCloud, Kthena not solely solves tangible inference challenges but in addition embodies the way forward for Cloud Native AI—an open, clever ecosystem worthy of our long-term funding and deep engagement.”
—— Paco Xu, Open Supply Staff Lead at DaoCloud, Member of Kubernetes Steering Committee
“Deploying and managing self-hosted LLM inference providers at manufacturing scale is a posh methods engineering problem. It encompasses all the lifecycle—deployment, operations, elasticity, and restoration—alongside vital necessities like GPU stability, scheduling effectivity, and AI observability. Kthena is engineered particularly to handle these complexities.
Throughout Kthena’s planning section, the Xiaohongshu Cloud Native group engaged deeply with contributors to co-design varied clever site visitors scheduling methods. Shifting ahead, we are going to proceed our collaboration on the AI Gateway entrance. By leveraging Xiaohongshu’s manufacturing insights, we goal to offer the neighborhood with production-ready capabilities, together with granular site visitors scheduling, mannequin API administration, and MCP protocol assist.”
—— Kong Gu (Huachang Chen), Cloud Native Enterprise Gateway Lead, Xiaohongshu
“After an in-depth analysis of Kthena, China Unicom Cloud is impressed by its forward-looking design. We’re notably enthusiastic about its joint scheduling capabilities with Volcano.
Options like topology consciousness and Gang Scheduling immediately deal with the vital effectivity and reliability challenges inherent in large-scale distributed inference, providing a promising resolution to complicated scheduling bottlenecks.
We imagine Kthena’s superior low latency, excessive throughput, and clever routing will present the open-source neighborhood with a really production-ready resolution, empowering builders to construct and handle cloud native AI purposes with larger effectivity.”
—— Zhaoxu Lu, Staff Lead, Clever Computing Heart, China Unicom Cloud
“Openness and collaboration gas innovation. Inside the CNCF ecosystem, we’re devoted to driving infrastructure in direction of an ‘AI Native’ future.
By launching the Kthena sub-project, the Volcano neighborhood applies its confirmed experience in batch computing—like topology consciousness and Gang scheduling—to on-line LLM inference. Kthena introduces important cloud native scheduling primitives, enabling complicated LLM workloads to run effectively as first-class residents in Kubernetes.
We invite builders worldwide to hitch us in refining this vital infrastructure and accelerating the AI Native period.”
—— Kevin Wang, Volcano Maintainer, CNCF TOC Vice Chair
Begin Exploring Kthena Right now
That is only the start. We plan to assist extra environment friendly scheduling algorithms and broader greatest practices for giant mannequin deployment.
Be a part of us to unlock the total potential of Cloud Native LLMs!